


Drupal rappresenta oggi non solo la miglior soluzione CMS di livello enterprise, ma anche quella che integra l’intelligenza artificiale in modo più maturo. La release 1.3.0 del modulo Drupal AI, ricchissima di funzionalità, segna un passaggio importante da integrazione sperimentale a piattaforma pronta per la produzione. L’adozione degli LLM nei CMS aziendali è stata finora frenata da rischi tangibili legati alla privacy dei dati, alle allucinazioni dei modelli e alla mancanza di osservabilità sulle operazioni eseguite in background. Questa versione affronta tali criticità strutturali, introducendo funzionalità di governance avanzate, flussi di telemetria standardizzati e strumenti di orchestrazione che trasformano le sperimentazioni in architetture solide.
Il team di SparkFabrik ha svolto un ruolo attivo nello sviluppo del modulo principale, guidando la progettazione dei sistemi di sicurezza e di ricerca avanzata. L’approccio ingegneristico Cloud Native ha permesso di applicare i principi di sicurezza by-design e DevSecOps direttamente all’intelligenza artificiale, garantendo che ogni interazione sia tracciabile e sicura.
Per comprendere l’estensione di questo ecosistema, è utile consultare la nostra panoramica completa sulle funzionalità AI in Drupal. Come illustrato nel video di approfondimento di Marcus Johansson, Tech Lead della Drupal AI Initiative, l’aggiornamento fornisce fondamenta architetturali per operazioni complesse. Abbiamo dettagliato il percorso di queste implementazioni nel nostro articolo dedicato a come abbiamo plasmato il futuro di Drupal AI nel 2025, dimostrando come l’integrazione dei modelli linguistici richieda competenze trasversali tra sviluppo CMS e infrastrutture distribuite.
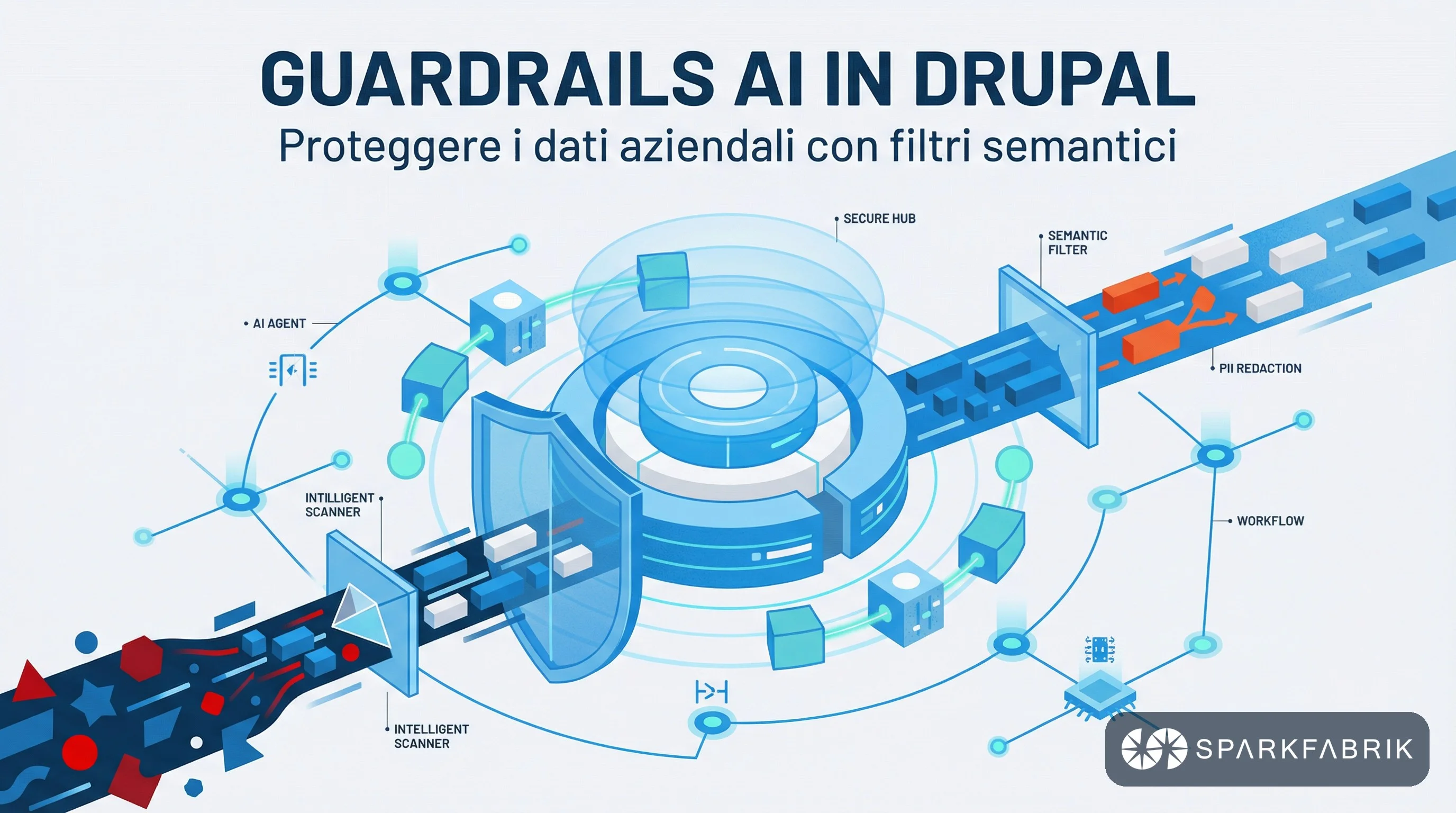
Perché i Guardrails AI trasformano Drupal in una piattaforma enterprise sicura?
I Guardrails AI trasformano Drupal in una piattaforma sicura fungendo da filtri bidirezionali che intercettano le richieste e validano le risposte dei Large Language Models. Questo sistema di governance blocca la fuga di dati sensibili e previene le allucinazioni, garantendo la conformità necessaria per le applicazioni enterprise in produzione.
L’implementazione di queste policy contribuisce ad aumentare la conformità sulle interazioni con gli LLM, in uscita ed in entrata. Per approfondire il design di questi componenti, è possibile analizzare le strategie architetturali per mitigare i rischi dei modelli linguistici nell’articolo di dettaglio sui Guardrails in DrupalAI.
Durante l’evento Drupal X Business, Luca Lusso ha presentato nel dettaglio il funzionamento di questi meccanismi di protezione. Nel suo talk ha evidenziato come l’implementazione di regole ferree sposti l’intelligenza artificiale da un paradigma sperimentale a uno strumento governabile. L’approccio Cloud Native adottato nella progettazione assicura che questi controlli operino in modo efficiente, mantenendo la latenza molto contenuta così da non impattare negativamente i processi editoriali.
Intercettazione e mascheramento dei dati sensibili
I Guardrails operano a un livello profondo dell’architettura, impedendo la fuga di dati sensibili prima che la richiesta HTTP lasci i server aziendali. Questo include il blocco di PII (Personally Identifiable Information), dati finanziari o proprietà intellettuale. Il sistema può bloccare interamente la richiesta o mascherare l’input utilizzando espressioni regolari o servizi di validazione esterni come AWS Bedrock.
Un esempio pratico illustra l’efficacia di questo approccio. Se un redattore inserisce in un prompt il nome in codice di un prodotto secretato, come il progetto interno “MDX 250”, il Guardrail configurato intercetta immediatamente il testo. O, molto più banalmente, se un utente invia nel prompt i propri dati personali o il codice della carta di credito, il sistema li blocca o li oscura prima dell’invio a LLM pubblici come quelli di OpenAI o Anthropic.
Questa validazione preventiva garantisce la sicurezza della supply chain del dato, assicurando che l’infrastruttura aziendale non diventi un veicolo per la dispersione di segreti industriali. L’applicazione di questi filtri avviene in tempo reale e fornisce un feedback immediato all’utente. Spiegando esattamente quale policy di sicurezza è stata violata, il sistema mantiene un alto livello di consapevolezza tra i team editoriali.
Architettura agnostica e validazione bidirezionale
Il sistema di Guardrails è progettato con una rigorosa architettura agnostica, il che significa che non è legato a un singolo vendor o a un modello linguistico specifico. Questa indipendenza permette alle organizzazioni di definire policy di sicurezza centralizzate. Tali regole rimangono valide anche se si decide di migrare da un provider cloud all’altro, abbattendo i costi di refactoring.
La protezione offerta dal modulo si articola su tre livelli di intervento distinti:
- Blocco preventivo della richiesta in uscita, che analizza il prompt dell’utente e il contesto fornito per identificare violazioni delle policy aziendali prima di qualsiasi comunicazione di rete.
- Riformattazione o blocco della risposta in ingresso, che analizza l’output generato dal modello linguistico per intercettare contenuti inappropriati, linguaggi offensivi o risposte che violano le direttive etiche.
- Prevenzione delle allucinazioni e mantenimento del tone of voice aziendale, garantendo che il modello non inventi fatti inesistenti o utilizzi uno stile di comunicazione estraneo alle linee guida del brand.
Questa validazione bidirezionale assicura che il CMS mantenga l’autorità finale sui contenuti. L’intelligenza artificiale viene trattata come un fornitore di servizi che deve essere costantemente supervisionato da logiche di business rigide.
Come il Reranking semantico migliora le architetture RAG su Drupal AI?
Il Reranking semantico migliora le architetture RAG su Drupal introducendo un secondo passaggio di valutazione basato sull’intelligenza artificiale. Dopo il filtraggio vettoriale iniziale, un modello specializzato riordina i documenti recuperati analizzandone la reale pertinenza contestuale, garantendo che i Large Language Models ricevano informazioni precise per generare le risposte.
Il nuovo operation type di Reranking rappresenta un’altra area di forte contributo da parte di SparkFabrik, essenziale per implementare architetture Retrieval-Augmented Generation efficaci. L’adozione di queste tecniche avanzate richiede un nuovo approccio architetturale orientato agli agenti AI, dove la precisione del recupero delle informazioni determina direttamente la qualità dell’output finale.
Le società di sviluppo si scontrano frequentemente con i limiti della ricerca vettoriale pura, che spesso recupera documenti simili ma non contestualmente rilevanti. Implementando il reranking, abbiamo osservato una riduzione del 70% nei “falsi positivi” durante le interrogazioni documentali complesse ed un ordinamento dei risultati più efficace. Questo filtro semantico profondo assicura che il modello linguistico riceva solo il contesto strettamente necessario, ottimizzando anche il consumo di token.
Superare i limiti della ricerca vettoriale standard
Un database vettoriale standard restituisce risultati basati esclusivamente sulla distanza matematica tra le coordinate dei testi nello spazio multidimensionale. Sebbene questo metodo sia veloce e utile per scremare grandi volumi di dati, non sempre comprende le sfumature linguistiche o l’intento reale dietro una query complessa. L’ordine dei documenti forniti come contesto a un LLM influisce significativamente sulla qualità della risposta finale. I modelli tendono infatti a dare maggiore peso alle informazioni presentate per prime, nonostante le context-windows sempre più ampie.
Il re-ranking opera come un secondo passaggio chiave. Dopo che il motore di ricerca vettoriale ha recuperato un set iniziale di documenti, ad esempio i primi cinquanta risultati, un modello specializzato analizza questo sottoinsieme. Il modello valuta la reale pertinenza semantica di ciascun documento rispetto alla domanda specifica, assegnando un nuovo punteggio di rilevanza.
Questo processo riordina i risultati, portando in cima i documenti che contengono effettivamente la risposta, anche se matematicamente non erano i più vicini alla query originale. Il risultato è un contesto ottimizzato che viene poi passato al modello linguistico generativo, riducendo drasticamente il tasso di errore.
Integrazione nativa tra Vector Database e LLM
Il flusso tecnico implementato nella versione 1.3 prevede una solida integrazione tra un motore di ricerca avanzato, come Typesense (di cui siamo maintainer del modulo Drupal) o un database relazionale con estensione vettoriale, e il provider AI scelto. Drupal orchestra questa comunicazione in modo trasparente. Prima interroga il database per ottenere i candidati, poi invia i risultati al servizio di reranking e infine passa i documenti riordinati al modello generativo.
Questa architettura a due stadi aumenta l’affidabilità dei sistemi conversazionali. Nei chatbot documentali interni, i dipendenti ottengono risposte precise basate sulle procedure aziendali corrette. Sulle piattaforme e-commerce, le ricerche semantiche restituiscono prodotti che corrispondono all’intento di acquisto dell’utente, migliorando sensibilmente i tassi di conversione.
Trattando il reranking come un’operazione agnostica, l’infrastruttura permette di utilizzare modelli specializzati (es. cross-encoder) addestrati appositamente per il task di riordino semantico. Questi modelli sono architetturalmente diversi e molto più precisi in questa fase rispetto all’uso di un LLM generativo. Gli LLM generativi più potenti e costosi possono così essere riservati solo per la generazione finale del testo. Questa separazione dei compiti ottimizza i costi operativi e diminuisce i tempi di latenza complessivi del sistema.

Osservabilità Cloud Native e gestione avanzata delle API
L’osservabilità Cloud Native nel modulo Drupal AI si concretizza attraverso l’integrazione dello standard OpenTelemetry. Questa architettura permette di tracciare ogni singola richiesta ai modelli linguistici, monitorando in tempo reale metriche cruciali come la latenza, il consumo di token e i costi operativi, trattando l’intelligenza artificiale come un microservizio misurabile.
L’implementazione dell’intelligenza artificiale in ambienti di produzione richiede metriche precise e un controllo rigoroso sulle risorse. Questa necessità si collega esplicitamente all’esperienza ingegneristica di SparkFabrik, dove l’AI non è vista come una scatola nera, ma come un componente distribuito. Per comprendere appieno questa filosofia architetturale, è utile esplorare i fondamenti e i vantaggi dell’approccio Cloud Native.
La versione 1.3 di Drupal AI introduce il supporto nativo a OpenTelemetry, permettendo di tracciare l’intero ciclo di vita di un agente autonomo. Questo livello di trasparenza è necessario per diagnosticare colli di bottiglia e ottimizzare le performance. Avere visibilità esatta sui costi per singola transazione AI permette ai CTO di giustificare gli investimenti tecnologici di fronte agli stakeholder aziendali con dati inoppugnabili.
Tracciamento distribuito con OpenTelemetry
L’esportazione standardizzata di metriche, span e trace consente ai team operativi di analizzare ogni singola richiesta AI con una granularità elevata. Quando un redattore richiede la generazione di un riassunto, il sistema registra esattamente quanto tempo il provider ha impiegato per rispondere. Vengono inoltre tracciati quanti token di contesto sono stati inviati e quanti token di completamento sono stati generati.
Questi dati permettono di calcolare i costi operativi in tempo reale, associando la spesa a specifiche funzionalità del sito o a determinati flussi editoriali. L’approccio basato su standard aperti garantisce la compatibilità con gli strumenti di mercato più diffusi, come Honeycomb, Grafana e Datadog. I team DevOps possono visualizzare le prestazioni dell’intelligenza artificiale sulle stesse dashboard utilizzate per monitorare il database o i cluster Kubernetes.
L’adozione di OpenTelemetry evita il lock-in sui tool di monitoraggio proprietari dei singoli vendor cloud. Indipendentemente dal fatto che l’infrastruttura utilizzi modelli ospitati su AWS, Google Cloud o soluzioni locali, il formato dei dati di osservabilità rimane coerente. Questo approccio unificato semplifica enormemente la gestione delle operazioni IT su larga scala.
Rate limiting, failover e metadata normalizzati
La gestione avanzata delle API nella versione 1.3 trasforma il modo in cui Drupal comunica con i provider esterni. Il sistema introduce soglie di rate limit e timeout per le richieste HTTP configurabili direttamente dall’interfaccia utente. Questa novità elimina la necessità di scrivere codice custom per gestire le limitazioni imposte dai servizi cloud.
Questa evoluzione porta con sé vantaggi architetturali rilevanti per la stabilità della piattaforma:
- Implementazione di logiche di failover automatico, che deviano il traffico verso un modello secondario o un provider alternativo quando il servizio principale raggiunge il limite di richieste consentite.
- Gestione sicura delle chiamate asincrone, permettendo agli agenti AI di eseguire compiti complessi in background senza bloccare i processi principali del server web o causare timeout per gli utenti.
- Normalizzazione dei metadati, che fornisce informazioni coerenti sui costi dei modelli e sulle capacità tecniche indipendentemente dal provider scelto, facilitando il passaggio da un fornitore all’altro.
Questi meccanismi di protezione assicurano che un picco di richieste alle funzionalità intelligenti del sito non comprometta la disponibilità generale del CMS. La piattaforma degrada in modo controllato, mantenendo operativi i servizi critici e garantendo una continuità operativa di livello enterprise.
L’ecosistema di automazione: dai workflow editoriali alla moderazione AI
L’ecosistema di automazione di Drupal AI ottimizza i workflow editoriali integrando capacità decisionali direttamente nell’interfaccia di gestione dei contenuti. Attraverso strumenti come le Field Widget Actions e la moderazione automatizzata, il sistema riduce il carico cognitivo dei team, trasformando compiti manuali complessi in processi fluidi e immediati.
Queste funzionalità di automazione rendono l’offerta di un’azienda di sviluppo software AI immediatamente tangibile per il business. L’impatto si traduce in un ritorno sull’investimento basato sul risparmio di tempo e sulla riduzione degli errori umani (un risparmio stimato di oltre 20 ore settimanali di revisione e moderazione manuale per i team editoriali di medie dimensioni). L’obiettivo è semplificare la gestione dei contenuti integrando l’AI in modo trasparente nelle operazioni quotidiane.
I miglioramenti all’interfaccia utente includono un nuovo editor Markdown per la stesura dei prompt di sistema. Questa scelta tecnica è particolarmente utile poiché i modelli linguistici interpretano il formato Markdown in modo molto più efficiente rispetto all’HTML o al testo semplice, ed è anche possibile dare una migliore struttura ai prompt.
Non da ultimo, il Context Control Center permette di definire una sola volta tone of voice, audience, policy e dettagli aziendali specifici, in un unico ambiente ed una sola volta. Le varie parti del contesto possono quindi essere usati dai vari team redazionali, a supporto delle loro attività.
Il CCC supporta anche l’autocompletamento di variabili e token, permettendo quindi agli amministratori di “iniettare” dinamicamente i dati dell’utente corrente o del nodo all’interno delle istruzioni inviate al modello. Questo aumenta la precisione complessiva del contesto, migliorando di conseguenza anche la qualità dell’output dell’LLM.
E, ricollegandoci all’osservabilità, anche il CCC ha funzionalità di usage tracking, logging, agent debugging ed un’ampia gamma di test automatizzati che coprono tutte le sue features, aspetti fondamentali per gli engineers.
Moderazione dei contenuti e Object Detection
La moderazione dei contenuti basata sull’intelligenza artificiale introduce un livello di controllo automatizzato sui testi inseriti dagli utenti o dai redattori. Il sistema analizza il contenuto in tempo reale e può alterare autonomamente lo stato di moderazione del nodo. Ad esempio, se viene rilevato un linguaggio inappropriato, lo stato passa automaticamente da pubblicato a segnalato, richiedendo l’intervento di un supervisore umano.
Parallelamente, l’integrazione dell’Object Detection espande le capacità di analisi ai contenuti multimediali. Utilizzando modelli di computer vision o algoritmi di deep learning, spesso eseguiti localmente o tramite piattaforme come Hugging Face, il sistema riconosce oggetti specifici all’interno delle immagini caricate. Questa tecnologia restituisce le coordinate esatte degli elementi identificati, permettendo validazioni complesse.
Un caso d’uso tipico riguarda il blocco degli upload che non rispettano le linee guida aziendali. Il sistema può impedire il caricamento di un’immagine se non rileva la presenza di un dispositivo di sicurezza specifico in una foto di cantiere. Oppure può rifiutare immagini che contengono loghi della concorrenza, automatizzando un processo di controllo qualità che richiederebbe ore di lavoro manuale.
Field Widget Actions per dati strutturati
Le Field Widget Actions rappresentano l’integrazione più profonda dell’automazione all’interno dell’esperienza editoriale, portando le capacità generative direttamente sui singoli campi di Drupal. Invece di utilizzare un chatbot generico, il redattore dispone di pulsanti contestuali che eseguono operazioni specifiche sui dati in fase di inserimento.
I casi d’uso tecnici introdotti (o migliorati) nella versione 1.3 coprono un ampio spettro di necessità operative:
- Estrazione di indirizzi fisici da testi non strutturati, normalizzando le informazioni geografiche tramite integrazioni con servizi come Google Places per popolare automaticamente i campi mappa.
- Generazione di meta tag SEO ottimizzati, creando titoli accattivanti e descrizioni pertinenti basandosi sull’analisi del contenuto testuale del nodo.
- Conversione di dati testuali grezzi in formati JSON rigorosamente strutturati, un passaggio essenziale per esporre informazioni coerenti tramite API in architetture headless.
- Creazione automatica di sezioni FAQ a partire da documenti lunghi e operazioni di text-to-speech che trasformano gli articoli testuali in file audio associati ai campi media.
Queste azioni trasformano il CMS da un semplice contenitore di informazioni a un assistente attivo. Costringendo i modelli linguistici a rispettare schemi di dati predefiniti, il sistema garantisce che l’output generato sia immediatamente utilizzabile dalle logiche di visualizzazione del sito. Questo approccio riduce drasticamente la necessità di interventi manuali di pulizia e formattazione. Non da ultimo, tali funzioni sono facilmente utilizzabili da chiunque, senza particolari competenze tecniche.
Conclusione
Drupal AI 1.3 rappresenta un aggiornamento importante che mette in evidenza la maturità dell’ecosistema. Fornendo strumenti avanzati come i Guardrails per la sicurezza, il Reranking per la precisione semantica e l’integrazione con OpenTelemetry per l’osservabilità, il modulo offre l’infrastruttura necessaria per operare in ambienti enterprise complessi e regolamentati.
L’integrazione sicura dei modelli linguistici all’interno dei processi aziendali richiede competenze trasversali che vanno ben oltre la semplice installazione di un plugin. È necessaria una profonda comprensione dello sviluppo CMS, delle architetture distribuite Cloud Native e delle rigorose pratiche di data governance. Solo un approccio integrato, guidato da metodo ed esperienza, garantisce che l’innovazione tecnologica non comprometta la sicurezza o le prestazioni del sistema.
Per orchestrare queste tecnologie in modo scalabile e sicuro, il valore aggiunto risiede nell’affidarsi a partner tecnologici con una comprovata esperienza nelle dinamiche open source e nello sviluppo di software basato sull’intelligenza artificiale personalizzato. L’evoluzione di Drupal dimostra che il futuro della gestione dei contenuti appartiene alle piattaforme capaci di unire la flessibilità editoriale con il rigore ingegneristico. Contatta i nostri esperti e parlaci delle tue sfide per scoprire come implementare queste soluzioni nella tua architettura.