


L’integrazione di sistemi autonomi all’interno delle architetture aziendali impone una revisione profonda delle pratiche di ingegneria del software. L’AgentOps è la nuova disciplina che governa il ciclo di vita degli agenti AI autonomi, un prerequisito per governance, sicurezza ed osservabilità, specialmente per flussi critici in contesti enterprise.
Fino a poco tempo fa, il monitoraggio delle applicazioni si basava su un presupposto fondamentale: il software tradizionale è deterministico. A parità di input e di stato iniziale, un microservizio restituisce sempre lo stesso output.
L’adozione dei Large Language Models ha infranto questa certezza, introducendo componenti intrinsecamente probabilistici all’interno dei flussi di lavoro critici.
Questo articolo si rivolge a DevOps engineer, tech lead e platform engineer che si trovano ad affrontare una sfida operativa inedita. Non si tratta più di verificare semplicemente se un servizio risponde alle richieste di rete, ma di valutare se le decisioni prese da un’entità autonoma siano corrette, sicure e allineate agli obiettivi di business. Quando un agente AI fallisce, raramente genera un errore di sistema evidente; più spesso produce un’allucinazione semantica, entra in un loop di ragionamento infinito o esegue chiamate API non previste.
I tradizionali sistemi di monitoraggio, focalizzati su metriche infrastrutturali come l’utilizzo della CPU, il consumo di memoria RAM o la latenza di rete, risultano del tutto inefficaci di fronte a queste anomalie comportamentali. Un pod Kubernetes può apparire perfettamente sano sulle dashboard operative, mentre al suo interno un agente sta consumando migliaia di token in un ciclo decisionale errato.
L’AgentOps nasce esattamente per risolvere questo vuoto di visibilità e controllo. Non si tratta di un semplice insieme di nuovi strumenti software, ma dell’evoluzione necessaria per portare l’intelligenza artificiale autonoma a un livello enterprise-ready.
Abbracciare questa disciplina significa estendere il rigore ingegneristico, tipico degli ambienti Cloud Native, alla gestione del ciclo di vita dei modelli generativi, garantendo che la loro autonomia si traduca in un vantaggio competitivo reale e non in un rischio operativo incontrollabile.
Cosa definisce l’AgentOps rispetto alle tradizionali discipline operative?
L’AgentOps è la disciplina ingegneristica dedicata alla gestione, al monitoraggio e alla governance del ciclo di vita degli agenti AI autonomi in produzione. A differenza delle operazioni IT tradizionali, si concentra sull’osservabilità e la governance dei processi decisionali stocastici, garantendo che i sistemi multi-agente operino in modo sicuro e prevedibile.
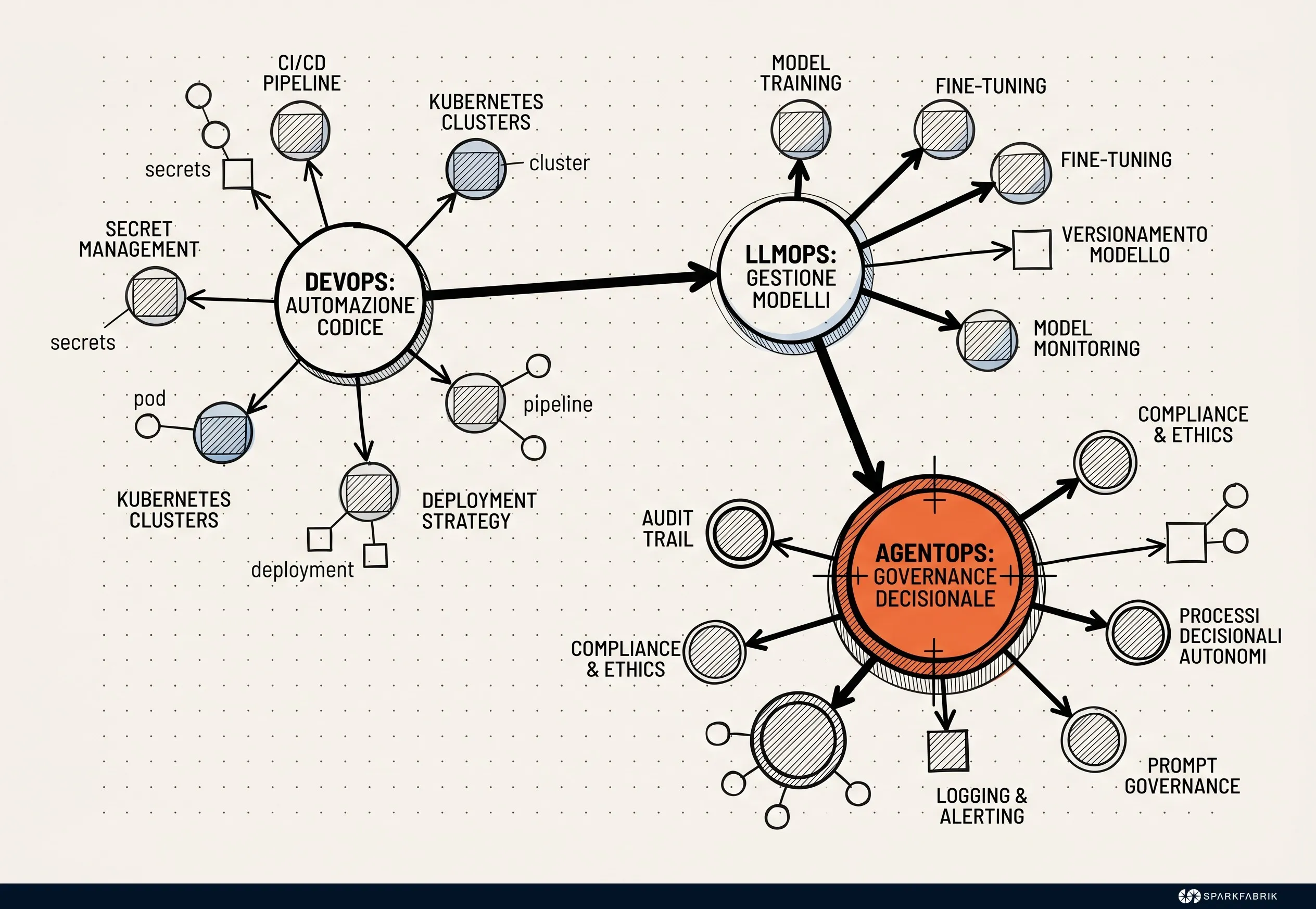
Definire il perimetro esatto di questa materia richiede di tracciare i confini rispetto alle metodologie preesistenti, seppur vi siano ovviamente legami profondi. Come evidenziato in recenti studi accademici, il passaggio epocale consiste nel transitare dalla gestione di macchine che eseguono istruzioni deterministiche alla supervisione di entità decisionali stocastiche. Un cambiamento non solo tecnico, ma anche mentale e di approccio.
L’AgentOps non deve essere confuso con l’AIOps, che utilizza algoritmi di machine learning per ottimizzare le operazioni IT classiche prevedendo guasti o analizzando log. Allo stesso modo, si distingue nettamente dall’LLMOps, che si limita all’addestramento, al fine-tuning e al deployment dei modelli base. Il focus dell’AgentOps è il comportamento dell’agente nel suo complesso: l’uso degli strumenti, la gestione della memoria, la pianificazione delle azioni e l’interazione con l’ambiente circostante.
Questa transizione comporta una profonda evoluzione del ruolo del DevOps engineer. I professionisti dell’infrastruttura devono ora acquisire competenze per gestire l’imprevedibilità semantica. Non basta più garantire l’uptime del cluster; diventa essenziale configurare sistemi capaci di intercettare derive comportamentali prima che si traducano in azioni distruttive.
Se l’obiettivo iniziale era capire cos’è il DevOps per automatizzare il rilascio del codice, oggi la sfida è governare l’intelligenza artificiale. Per esplorare le origini di questo cambiamento metodologico, ti invitiamo ad approfondire l’approccio DevOps e la sua evoluzione nello sviluppo applicativo.
La natura stocastica degli agenti AI
Il cuore del problema operativo risiede nella natura probabilistica dei modelli generativi. Le sfide di questo nuovo paradigma si dividono tipicamente tra anomalie intra-agente e anomalie inter-agente all’interno dei sistemi multi-agente. A livello intra-agente, i fallimenti assumono forme subdole: un agente può perdere il contesto operativo durante una conversazione prolungata, oppure soffrire di un’allucinazione di memoria all’interno di un’architettura Retrieval-Augmented Generation (RAG), recuperando documenti irrilevanti e basando su di essi azioni successive.
Nei sistemi multi-agente, la complessità scala rapidamente. Le anomalie inter-agente includono fenomeni come le tempeste di messaggi, dove due o più agenti entrano in un ciclo infinito di richieste e risposte senza mai giungere a una conclusione, consumando budget computazionale in modo silente.
In questi scenari, i log tradizionali sono ciechi. Un loop infinito di ragionamento non genera picchi anomali di CPU o latenze di rete tali da innescare gli allarmi standard. Il sistema infrastrutturale funziona perfettamente, è la logica applicativa autonoma a essere fallata. Per questo motivo, l’ingegneria operativa deve spostarsi dal monitoraggio delle risorse fisiche al monitoraggio semantico dei payload e delle catene di pensiero.
Quali sono le differenze tra AgentOps, DevOps, MLOps, LLMOps e AIOps?
Per orientarsi nel complesso ecosistema delle metodologie operative moderne, è utile mettere a confronto le diverse discipline. Ognuna di esse affronta un livello specifico dello stack tecnologico, contribuendo in modo incrementale alla stabilità e all’innovazione aziendale. L’AgentOps si posiziona al vertice di questa piramide, orchestrando l’automazione decisionale proattiva.
Di seguito, un’analisi strutturata delle principali discipline operative e del loro impatto sul business:
| Disciplina | Focus Principale | Impatto sul Business |
|---|---|---|
| DevOps | Automazione CI/CD e collaborazione | Riduzione del time-to-market, rilasci più frequenti e affidabili |
| DevSecOps | Sicurezza integrata (Shift-Left) | Mitigazione del rischio, compliance, riduzione dei costi di remediation |
| Platform Engineering | Standardizzazione tramite IDP | Riduzione del carico cognitivo, miglioramento della DevEx |
| MLOps | Ciclo di vita dei modelli ML | Rilascio affidabile di modelli predittivi, decisioni data-driven |
| LLMOps | Gestione di Large Language Models | Scalabilità delle applicazioni AI generative, ottimizzazione dei costi di inferenza |
| AIOps | AI applicata al monitoraggio IT | Prevenzione anomalie e alerting intelligente |
| AgentOps | Agenti AI autonomi per operations | Risoluzione proattiva e automazione decisionale |
Qual è il framework operativo per il ciclo di vita e l’osservabilità dell’AgentOps?
Il framework operativo dell’AgentOps struttura il ciclo di vita degli agenti attraverso sviluppo, validazione, deployment e manutenzione. Introduce l’osservabilità del ragionamento per tracciare le decisioni e implementa cicli di remediation per gestire anomalie semantiche, garantendo interventi rapidi e mirati sui comportamenti imprevisti in produzione.
Strutturare il ciclo di vita di un agente richiede un approccio metodologico rigoroso. Durante la fase di sviluppo, la definizione dei prompt e l’assegnazione degli strumenti devono essere trattate come codice sorgente, sottoposte a versionamento e peer review.
La validazione rappresenta un punto di svolta: i test unitari tradizionali non bastano, rendendo necessaria l’adozione di pattern come LLM-as-a-judge, dove modelli specializzati valutano la qualità, la pertinenza e la sicurezza delle risposte fornite dall’agente in ambienti di staging.
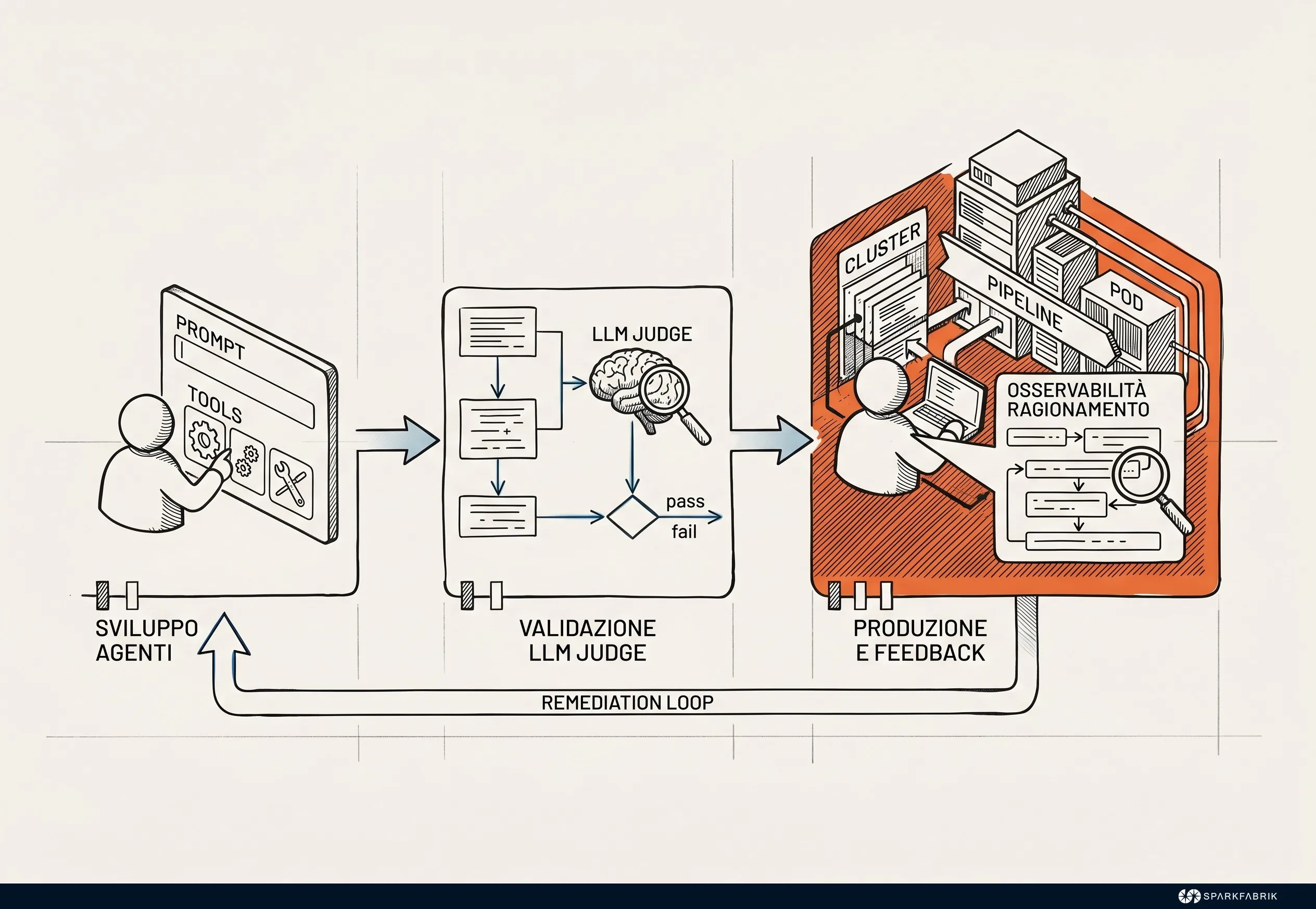
Anche in assenza di un LLM specializzato, è opportuno l’utilizzo di skill dedicate e di modelli differenti per le fasi di valutazione e generazione. Un paio di occhi freschi e imparziali, come nella peer review tra umani, è essenziale. Il modello giudice deve essere tipicamente diverso e preferibilmente dotato di capacità di ragionamento superiori rispetto al modello dell’agente per evitare bias di auto-valutazione.
Solo dopo aver superato questi benchmark dinamici, l’agente può passare alla fase di deployment e successiva manutenzione adattiva.
Il secondo pilastro del framework è la reasoning observability, ovvero l’osservabilità del ragionamento. Tracciare l’output finale di un agente è insufficiente per eseguire il debugging di un errore complesso. È indispensabile registrare l’intera catena di pensieri, i log di contesto, l’attivazione di guardrails e le specifiche chiamate ai tool esterni.
Questo livello di trasparenza è fondamentale per innescare un ciclo di gestione delle anomalie efficace, che consenta di eseguire una root cause analysis (RCA) accurata e di applicare risoluzioni mirate, come l’ottimizzazione del prompt o il rollback dello stato. Per comprendere come questi principi derivino dalla gestione di sistemi complessi, scarica la guida gratuita sulla SRE per garantire l’affidabilità delle applicazioni.
Osservabilità del ragionamento degli Agenti AI e telemetria
Estendere gli stack di osservabilità Cloud Native per supportare l’intelligenza artificiale autonoma è una delle sfide tecniche più affascinanti dell’AgentOps. Strumenti consolidati come Prometheus, Grafana e Jaeger, originariamente concepiti per il tracciamento dei microservizi, vengono ora configurati per supportare il tracing distribuito delle decisioni prese dai modelli generativi. Ogni passo del ragionamento dell’agente viene trattato come uno span all’interno di una traccia distribuita.
Questo approccio permette agli ingegneri di visualizzare esattamente quale frammento di contesto ha innescato una determinata chiamata API o perché l’agente ha deciso di ignorare un’istruzione specifica. Tuttavia, l’osservabilità del ragionamento introduce sfide inedite legate al volume dei dati. Il logging ad alta frequenza dei payload di input e output genera un carico enorme sui sistemi di telemetria.
Parallelamente, emerge la necessità cruciale di monitorare i costi. Poiché le API dei fornitori di modelli linguistici fatturano in base al consumo dei token, un agente bloccato in un loop decisionale può esaurire rapidamente il budget assegnato. Le dashboard di Grafana devono quindi essere estese per correlare le metriche di performance tecnica con le metriche finanziarie in tempo reale, implementando circuit breaker automatici che interrompano l’esecuzione quando le soglie di spesa vengono superate in modo anomalo.
In modo simile, nel caso si utilizzino modelli locali per garantire la massima sicurezza del dato, l’observability e il monitoraggio dei costi sono fondamentali e presentano sfide dedicate, richiedendo ad esempio un’attenta misurazione dell’utilizzo delle GPU e dei tempi di inferenza.
Gestione delle anomalie e remediation
I flussi di incident response specifici per l’intelligenza artificiale differiscono radicalmente da quelli tradizionali. Quando un agente AI manifesta un comportamento anomalo, l’obiettivo primario è contenere il raggio d’azione per prevenire danni all’infrastruttura o ai dati aziendali. Un rischio concreto è il tool poisoning, di cui un vettore d’attacco ben conosciuto è l’Indirect Prompt Injection. L’agente riceve dati manipolati recuperati da una fonte esterna che lo inducono a corrompere l’applicazione o eseguire chiamate API distruttive, come la cancellazione di database o la modifica di permessi di rete.
Per gestire queste emergenze, il framework AgentOps deve prevedere meccanismi di interruzione immediata. I sistemi di orchestrazione devono poter revocare istantaneamente le credenziali temporanee assegnate all’agente o isolarlo a livello di rete, bloccando qualsiasi comunicazione in uscita. La remediation non si limita al contenimento, ma richiede un’analisi profonda per evitare il ripetersi dell’incidente.
L’integrazione di concetti di versioning e rollback sicuri diventa essenziale. Ogni aggiornamento del comportamento di un agente deve essere trattato come una release software formale, sia esso una modifica al prompt di sistema, o l’aggiunta di un nuovo strumento o una nuova skill (ovvero un set di capacità o funzioni specifiche, come il tool-calling, che l’agente può invocare per risolvere sotto-task).
Se un nuovo comportamento si rivela instabile in produzione, i team operativi devono poter eseguire un rollback allo stato precedente in modo deterministico, ripristinando immediatamente l’affidabilità del servizio mentre conducono l’analisi post-mortem in ambienti isolati.
AgentOps nel platform engineering: come evolve l’Internal Developer Platform?
Nell’ambito del Platform Engineering, l’AgentOps trasforma le Internal Developer Platform, ovvero i portali centralizzati per il self-service degli sviluppatori, in ecosistemi intelligenti. Gli agenti autonomi innalzano la DevEx e riducono il carico cognitivo, orchestrando risorse complesse, abilitando il self-service ed operando all’interno di perimetri ben definiti dalle policy aziendali.
I dati di mercato confermano che ci troviamo in una fase di profonda trasformazione architetturale. Il report di ESG e Google Cloud evidenzia come il 55% delle aziende a livello globale abbia già adottato pratiche di platform engineering, e oltre il 90% preveda di espanderne l’uso nei prossimi anni.
Questa adozione massiccia crea il terreno infrastrutturale perfetto per l’AgentOps. Le piattaforme centralizzate forniscono le API, gli strumenti di orchestrazione e i sistemi di identity management necessari affinché gli agenti AI possano operare su larga scala.
La Developer Experience (DevExp) è un parametro fondamentale nel Platform Engineering per misurare l’efficacia di un team di ingegneria. Gli agenti AI integrati in una IDP rivoluzionano questa esperienza.
La transizione in atto vede le Internal Developer Platform evolversi da portali statici self-service, dove lo sviluppatore deve compilare moduli complessi, a ecosistemi realmente intelligenti e proattivi. Tuttavia, questa efficienza non può esistere senza una governance ferrea: l’automazione deve essere vincolata da policy as code per prevenire configurazioni errate.
Per approfondire l’impatto di queste dinamiche sull’efficienza dei team, ti consigliamo di leggere come migliorare la Developer Experience per ridurre il carico cognitivo dei team e la nostra guida dedicata.

Da portali statici a ecosistemi intelligenti
L’evoluzione delle piattaforme interne è guidata dalla necessità di ridurre il carico cognitivo sui team di sviluppo. In un’architettura a microservizi moderna, richiedere il provisioning di un nuovo ambiente comporta la configurazione di repository, pipeline CI/CD, cluster Kubernetes, database e policy di rete. Richiedere agli sviluppatori di padroneggiare ogni singolo strumento rallenta drasticamente la consegna del software.
Gli agenti AI risolvono questo collo di bottiglia orchestrando le risorse in autonomia. Uno sviluppatore può interagire con la piattaforma in linguaggio naturale, richiedendo ad esempio un ambiente di staging ottimizzato per test di carico su un servizio specifico. L’agente analizza la richiesta, deduce le dipendenze necessarie, genera i manifesti infrastrutturali e avvia il provisioning dinamico delle risorse, notificando l’utente a operazione conclusa.
L’abbattimento del carico cognitivo è immediato e quantificabile ed il valore di business generato da questa transizione è duplice. Da un lato, si ottiene un onboarding accelerato: i nuovi assunti possono diventare produttivi in pochi giorni anziché settimane, guidati dall’agente attraverso le complessità dell’infrastruttura aziendale. Dall’altro, si ottimizza il tempo degli sviluppatori senior, che vengono liberati da task operativi ripetitivi per concentrarsi sulla scrittura di logica di business e sull’innovazione architetturale.
AgentOps e DevSecOps: la sicurezza come prerequisito nell’era degli agenti autonomi
L’autonomia degli agenti AI genera valore solo se operano all’interno di un perimetro di sicurezza definito e automatizzato. Con l’AgentOps, il DevSecOps smette di essere una best practice e diventa un prerequisito infrastrutturale: ogni azione autonoma, dal provisioning di risorse alla modifica di una configurazione, deve essere validata prima di raggiungere la produzione. L’approccio Shift-Left, che integra la sicurezza fin dalle prime fasi del ciclo di vita del software, diventa il principio architetturale su cui costruire la fiducia nei sistemi autonomi.
Come validare le azioni degli agenti nelle pipeline DevSecOps?
L’implementazione pratica richiede che gli agenti AI operino all’interno di una pipeline DevSecOps rigorosa e immodificabile. Ogni proposta di modifica generata da un agente AI deve essere trattata come una pull request standard, soggetta all’intera catena di controlli automatizzati. Non esistono eccezioni: che l’azione sia stata prodotta da un ingegnere o da un agente, il processo di validazione è identico.
Questo significa integrare i giusti strumenti operativi direttamente nel flusso di lavoro dell’agente. Ogni modifica infrastrutturale generata dall’AI, prima di essere applicata, deve passare attraverso test di sicurezza statici (SAST), che analizzano il codice proposto alla ricerca di vulnerabilità note, e test dinamici (DAST) che verificano il comportamento dell’applicazione a runtime. Questo avviene direttamente nelle pipeline CI/CD, validando così le azioni proposte dagli agenti prima del deploy.
I sistemi di container scanning completano il quadro, confermando che le immagini utilizzate non contengano dipendenze compromesse. Se un agente suggerisce l’aggiornamento di una libreria per risolvere un bug prestazionale, lo scanning verifica che la nuova versione non introduca vulnerabilità note. Solo dopo aver superato questi controlli, la modifica può procedere.
Inoltre, in alcuni framework AgentOps avanzati, i segnali prodotti da questi processi, come rifiuti della pipeline, approvazioni, falsi positivi, risultati degli scan ed altre istruzioni specifiche, diventano dei feedback che affinano progressivamente il comportamento dell’agente. Un sistema che apprende e migliora la postura di sicurezza con l’uso.
Policy as Code e guardrail di sicurezza
L’autonomia concessa agli agenti all’interno della piattaforma richiede la definizione di confini rigidi e invalicabili. La governance di questo processo si fonda sull’adozione di Policy as Code. In ambito AgentOps, la sicurezza si implementa attraverso due tipologie distinte di controlli: i policy guardrail, che limitano le azioni infrastrutturali concrete, e gli AI guardrail, che filtrano semanticamente gli input e gli output dei modelli linguistici.
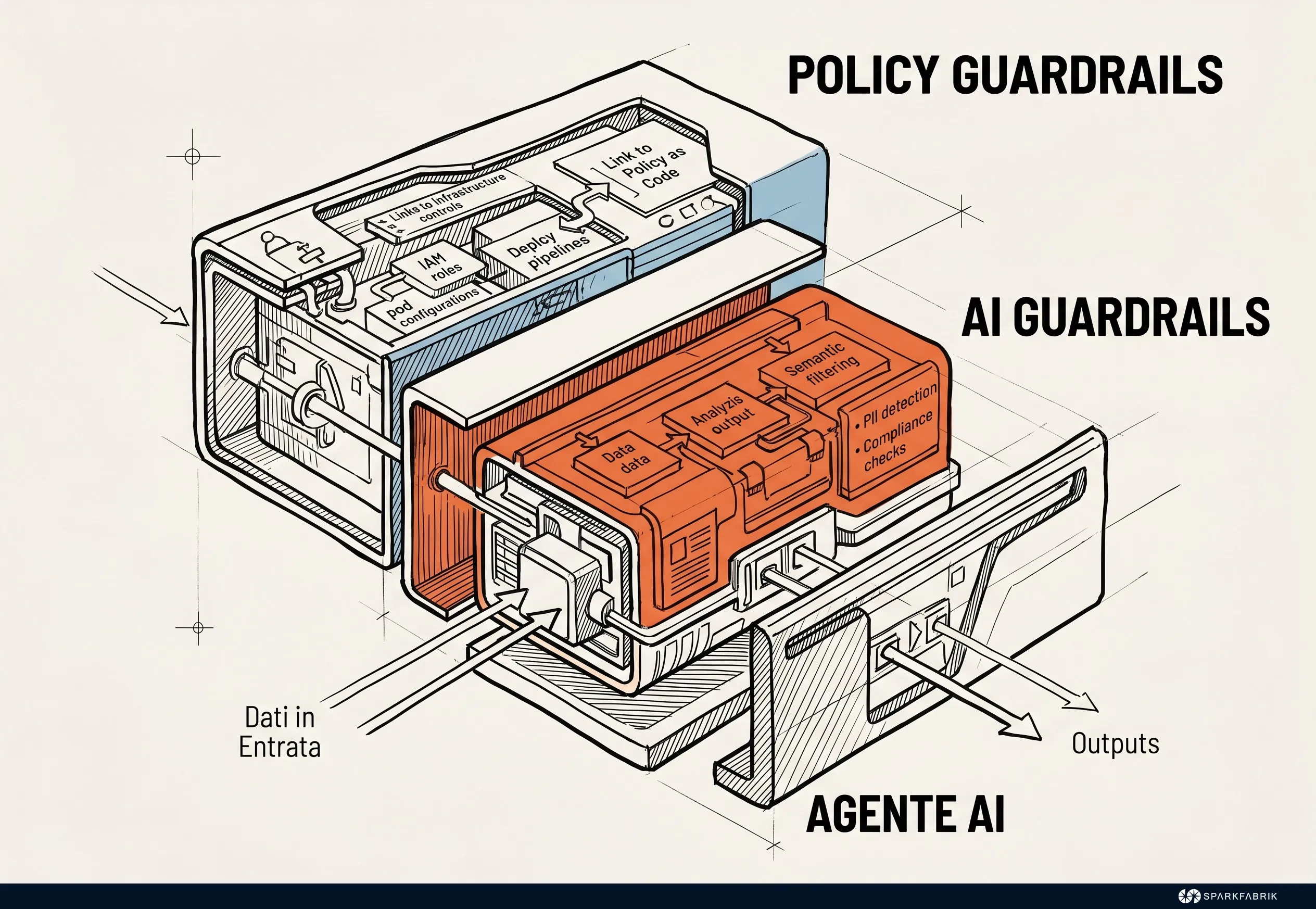
I policy guardrail sono vincoli infrastrutturali che limitano le azioni dell’agente e ne circoscrivono il raggio d’azione effettivo. Utilizzando standard come Open Policy Agent, le aziende definiscono regole che impediscono all’intelligenza artificiale di eseguire operazioni non conformi o distruttive (come l’esposizione di un database su reti pubbliche), indipendentemente dalle istruzioni ricevute o dalle deduzioni del modello.
Un esempio concreto chiarisce l’importanza di questi vincoli: immaginiamo un agente incaricato di ottimizzare i costi cloud che identifica un Web Application Firewall (WAF) apparentemente sottoutilizzato e decide autonomamente di spegnerlo per risparmiare risorse. Senza policy infrastrutturali, l’azione verrebbe eseguita, esponendo l’azienda a rischi critici. I policy guardrail intercettano la chiamata API, la bloccano in millisecondi e restituiscono all’agente un errore di conformità.
Un altro concetto distinto ma collegato è quello degli AI guardrail. Si tratta di sistemi che filtrano l’input e l’output semantico dell’agente, bloccando la generazione di contenuti dannosi o mascherando dati sensibili prima che vengano inviati ai modelli linguistici. Sono anche utilizzati per bloccare tentativi di prompt injection e risposte non in linea con il brand, evitando altrettanto seri danni reputazionali.
Anche questi filtri contribuiscono alla sicurezza delle applicazioni aziendali che integrano funzionalità AI, e richiedono monitoring e logging dettagliato per verificarne l’efficacia.
Un esempio pratico è illustrato nel nostro approfondimento sui Guardrails AI in Drupal: un contributo di SparkFabrik all’ecosistema open source che dimostra come configurare filtri di sicurezza avanzati per i dati in entrata e in uscita.
Come si applica l’AgentOps in contesti operativi reali?
L’AgentOps si applica trasversalmente a infrastruttura e software. Le regole di monitoraggio e governance governano sia i Virtual SRE per la gestione proattiva dei cluster Kubernetes, sia gli agenti applicativi che automatizzano la software delivery, il customer care e le operazioni di marketing.
Dimostrare l’universalità del framework AgentOps è fondamentale per comprenderne la portata strategica. L’errore più comune è relegare questa disciplina esclusivamente al monitoraggio dei chatbot. Al contrario, le pratiche di osservabilità, la gestione dei fallimenti semantici e l’imposizione di guardrail si applicano con la stessa efficacia sia all’infrastruttura di base che al software applicativo di alto livello. I principi ingegneristici non cambiano al variare del dominio di competenza dell’agente.
Per comprendere a fondo le fondamenta su cui operano questi agenti infrastrutturali, consulta la nostra guida completa a Kubernetes per l’orchestrazione dei container in ambienti complessi.
Virtual SRE per le operations infrastrutturali
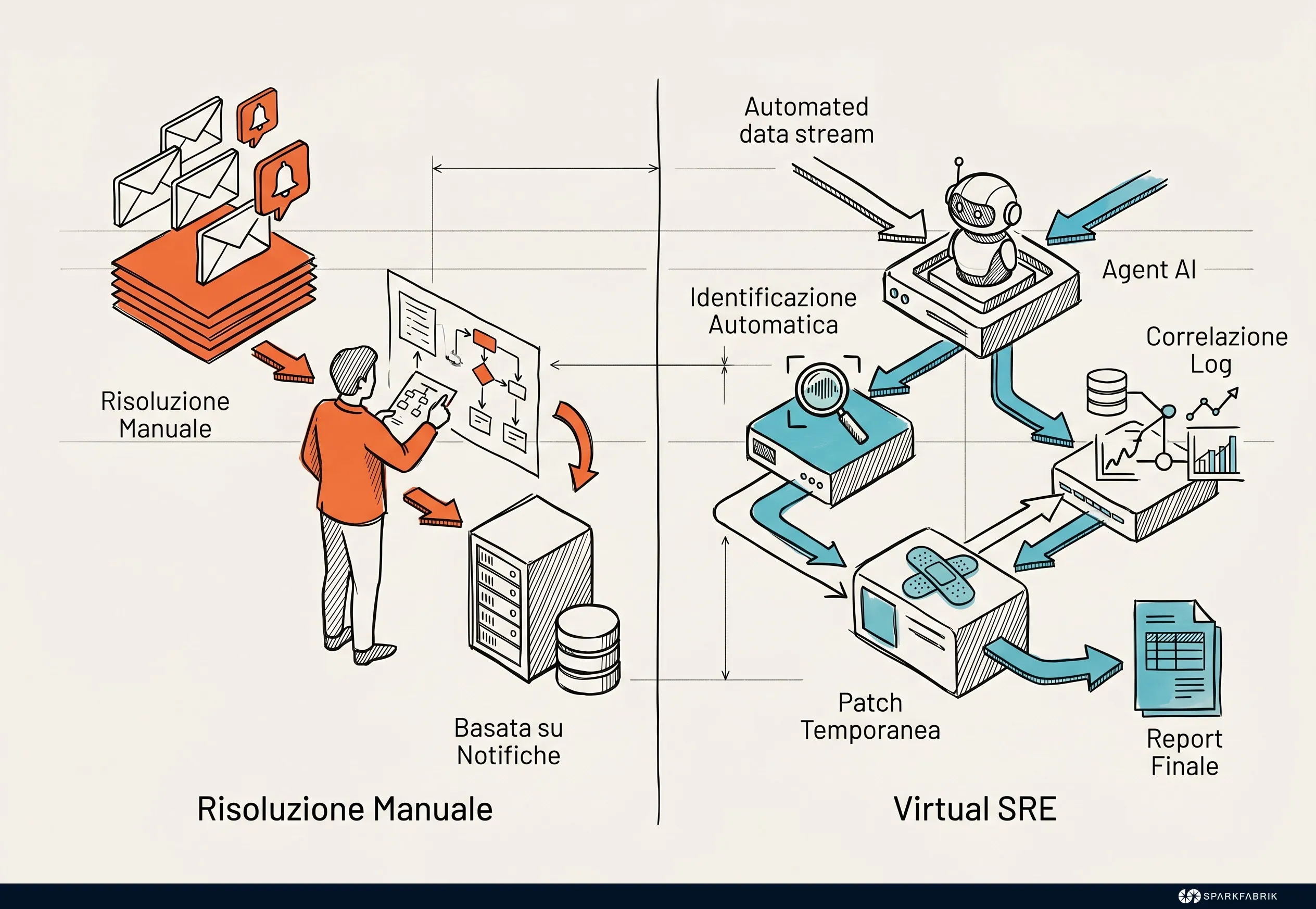
Un Virtual SRE è un agente autonomo progettato per identificare, diagnosticare e risolvere incidenti in produzione senza richiedere un intervento umano continuo. A differenza dei tradizionali copilot passivi, opera come un’estensione attiva del team di ingegneria, segnando uno dei traguardi più avanzati dell’AgentOps applicato all’infrastruttura.
Immaginiamo uno scenario operativo su un cluster Kubernetes: un microservizio inizia a manifestare un memory leak progressivo durante il fine settimana. I sistemi di alerting tradizionali invierebbero notifiche a un operatore reperibile, richiedendo un intervento manuale per analizzare i log, identificare il pod problematico e riavviarlo.
Un Virtual SRE (o SRE agent), dotato degli strumenti adeguati, intercetta l’anomalia in tempo reale. L’agente correla le metriche di consumo della memoria con i log applicativi recenti, identifica la causa probabile e applica una patch di configurazione temporanea, come l’aumento dei limiti di memoria o il riavvio controllato dei pod, notificando il team con un report dettagliato dell’incidente già risolto. Questo livello di automazione richiede un’osservabilità profonda per garantire che le azioni dell’agente non causino disservizi a cascata.
Scenari simili si applicano all’ottimizzazione delle pipeline CI/CD. Operando su ambienti cloud complessi, un agente può analizzare i tempi di esecuzione dei test interagendo direttamente con i repository Git. Se rileva che una suite di test end-to-end rallenta sistematicamente i rilasci senza trovare bug significativi, l’agente può proporre una riorganizzazione dei job o un parallelismo più efficiente, aprendo una pull request automatizzata per modificare le configurazioni della pipeline.
È cruciale sottolineare che l’AgentOps non sostituisce i team operativi, ma li potenzia. Il Virtual SRE affianca i team umani 24 ore su 24, ma il controllo strategico resta saldamente nelle mani degli ingegneri. Per abilitare questo livello di collaborazione servono osservabilità profonda, monitoraggio continuo, formazione dedicata e una forte propensione alla sperimentazione.
Agenti applicativi per software delivery e workflow
Spostando il focus fuori dall’infrastruttura, l’AgentOps dimostra il suo valore nella gestione di agenti specializzati in domini applicativi. Nella software delivery, i coding agent non si limitano a suggerire snippet di codice, ma generano intere funzionalità, eseguono revisioni di pull request e scrivono test unitari in autonomia. Il framework AgentOps assicura che il codice generato rispetti gli standard aziendali attraverso l’analisi statica automatizzata.
Un ambito in rapida espansione è il marketing agentico. In questo contesto, l’AgentOps governa sistemi complessi che analizzano le performance di centinaia di creatività pubblicitarie, le ricreano rispettando il tone of voice aziendale e orchestrano batch di A/B test in completa autonomia. Altri agenti specializzati si occupano di generare e ottimizzare landing page dinamiche in base al comportamento degli utenti. Sebbene il dominio sia creativo, la necessità di governance è prettamente ingegneristica.
Ancora, altri scenari applicativi si hanno nel customer care, nei processi commerciali e nella logistica, dove gli agenti gestiscono interazioni complesse con i clienti o ottimizzano le rotte di approvvigionamento elaborando enormi moli di dati in tempo reale.
La gestione di questi workflow richiede le medesime garanzie operative dell’infrastruttura. La necessità di implementare funzionalità di session replay per analizzare le interazioni passate, la valutazione continua della qualità tramite modelli giudicanti e la limitazione dell’autonomia per prevenire danni d’immagine o sprechi di budget rimangono identiche. L’AgentOps fornisce la struttura di controllo necessaria affinché l’intelligenza artificiale possa operare in modo sicuro in qualsiasi processo di business.
Come strutturare una roadmap di adozione dell’ AgentOps?
L’adozione dell’AgentOps richiede una roadmap pragmatica che parte dal consolidamento delle basi Cloud Native. Attraverso un approccio human-in-the-loop, i team costruiscono fiducia nel sistema validando le decisioni in sola lettura, prima di delegare operazioni a basso rischio all’autonomia supervisionata in produzione.
Fornire una guida chiara ai leader tecnologici è essenziale per evitare i fallimenti tipici dei progetti di innovazione non strutturati. Il percorso verso l’AgentOps non può prescindere dal consolidamento delle pratiche di automazione preesistenti. Implementare agenti intelligenti su infrastrutture gestite manualmente o prive di versionamento non porta all’efficienza, ma amplifica il debito tecnico.
Per esplorare l’impatto strategico di questa trasformazione, scopri come gli agenti intelligenti trasformano i processi e il business.
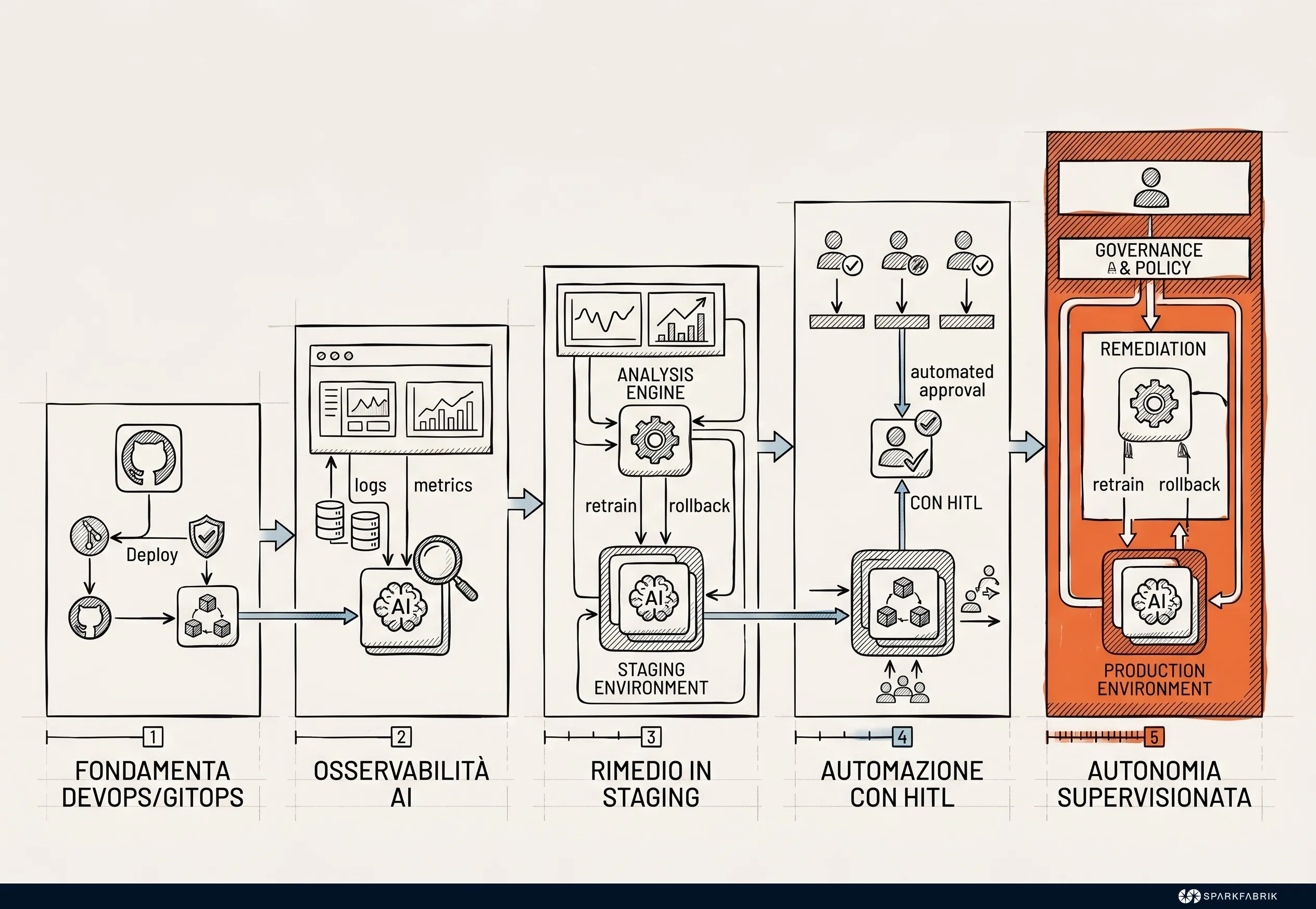
L’evoluzione verso l’autonomia si articola tipicamente attraverso una progressione logica:
- Assessment e standardizzazione GitOps: Le aziende devono mappare i propri processi operativi, identificare i colli di bottiglia e assicurarsi che l’infrastruttura sia dichiarativa e i deployment completamente automatizzati. Tentare di applicare l’AgentOps su processi manuali significa delegare all’intelligenza artificiale la gestione del caos. Inoltre, le pipeline DevSecOps diventano i gate obbligatori attraverso cui passano tutte le azioni degli agenti. Senza DevSecOps, dare autonomia a un agente è pericoloso.
- Osservabilità AI-Assisted (sola lettura): Gli agenti vengono introdotti senza alcun permesso di modifica. Il loro compito è analizzare enormi volumi di log, correlare eventi provenienti da sistemi distribuiti e generare reportistica avanzata sugli incidenti. Questo permette ai team di calibrare i sistemi di telemetria e valutare l’accuratezza del ragionamento.
- Remediation in ambienti non-prod: Gli agenti ottengono i permessi per applicare modifiche architetturali e risolvere incidenti, ma esclusivamente in ambienti di sviluppo e staging. In questo perimetro controllato, si testano le capacità di auto-correzione e si affinano i policy guardrail.
- Automazione human-in-the-loop in produzione: Gli agenti monitorano i cluster produttivi e propongono piani di risoluzione dettagliati, ma l’esecuzione effettiva richiede l’approvazione esplicita di un ingegnere senior. Questo garantisce la sicurezza assoluta in scenari reali ad alto stress.
- Autonomia supervisionata: Dopo mesi di validazione, compiti operativi specifici e a basso rischio, come l’ottimizzazione dei costi cloud o l’auto-scaling predittivo, vengono delegati completamente agli agenti. L’enfasi si sposta sulla robustezza dei sistemi di orchestrazione, capaci di isolare l’agente al primo segnale di anomalia.

Gestire l’incertezza dell’AgentOps come tecnologia emergente
Integrare l’AgentOps richiede un forte allineamento delle aspettative a livello direzionale. I CTO devono promuovere una cultura organizzativa caratterizzata da una spiccata propensione alla sperimentazione e da una sana tolleranza verso i fallimenti iniziali. Le “allucinazioni” dei modelli linguistici rappresentano un rischio concreto e, trattandosi di tecnologie emergenti, è naturale esplorare varie strategie di mitigazione.
Per gestire in sicurezza queste incertezze, è imperativo progettare sistemi che prevedano azioni di rollback istantaneo e immutabilità dell’infrastruttura. Se un agente AI applica una configurazione errata, il sistema di orchestrazione deve essere in grado di ripristinare rapidamente lo stato precedente. La resilienza è un valore sempre più centrale nelle architetture moderne e diventa il prerequisito per poter sperimentare in sicurezza con l’automazione autonoma.
L’approccio dello “human-in-the-loop” si conferma essenziale non solo come misura di sicurezza, ma come strumento di apprendimento organizzativo. La transizione da un approccio puramente AI-assisted (dove l’agente suggerisce e l’umano approva) a uno AI-autonomous deve essere graduale. Questo permette agli ingegneri di costruire fiducia nelle capacità decisionali dei modelli prima di allentare i vincoli operativi, e di mantenere l’intervento umano per le operazioni più critiche in produzione.
Conclusione
L’AgentOps non rappresenta una tendenza passeggera destinata a esaurirsi con il ciclo di hype dell’intelligenza artificiale. Al contrario, si afferma come un’evoluzione strutturale profonda, imprescindibile per gestire la complessità crescente dei sistemi distribuiti moderni.
Delegare l’operatività a entità decisionali stocastiche richiede un nuovo approccio, dove l’osservabilità del ragionamento e la gestione proattiva delle anomalie diventano le nuove metriche di successo per i team operativi.
È fondamentale ribadire che il successo dell’intelligenza artificiale autonoma in produzione poggia interamente sulla solidità delle fondamenta infrastrutturali. Senza un’architettura Cloud Native matura, priva di pratiche DevSecOps rigorose e di una gestione dichiarativa delle risorse, l’AgentOps rischia di amplificare le inefficienze esistenti. L’automazione intelligente non corregge i processi fallati, li esegue semplicemente a una velocità maggiore.
CTO, Tech Lead e responsabili dell’infrastruttura devono valutare con oggettività la maturità della propria Internal Developer Platform e le competenze interne in sicurezza, prima di delegare operazioni critiche agli agenti AI. Costruire ecosistemi intelligenti richiede pianificazione, competenze specialistiche e un approccio security-by-design.
Se desideri esplorare come la nostra esperienza possa accelerare questa transizione nella tua azienda, scopri come integriamo agenti intelligenti nei flussi di lavoro aziendali e prenota una consulenza per parlarci del tuo progetto e delle tue sfide.










