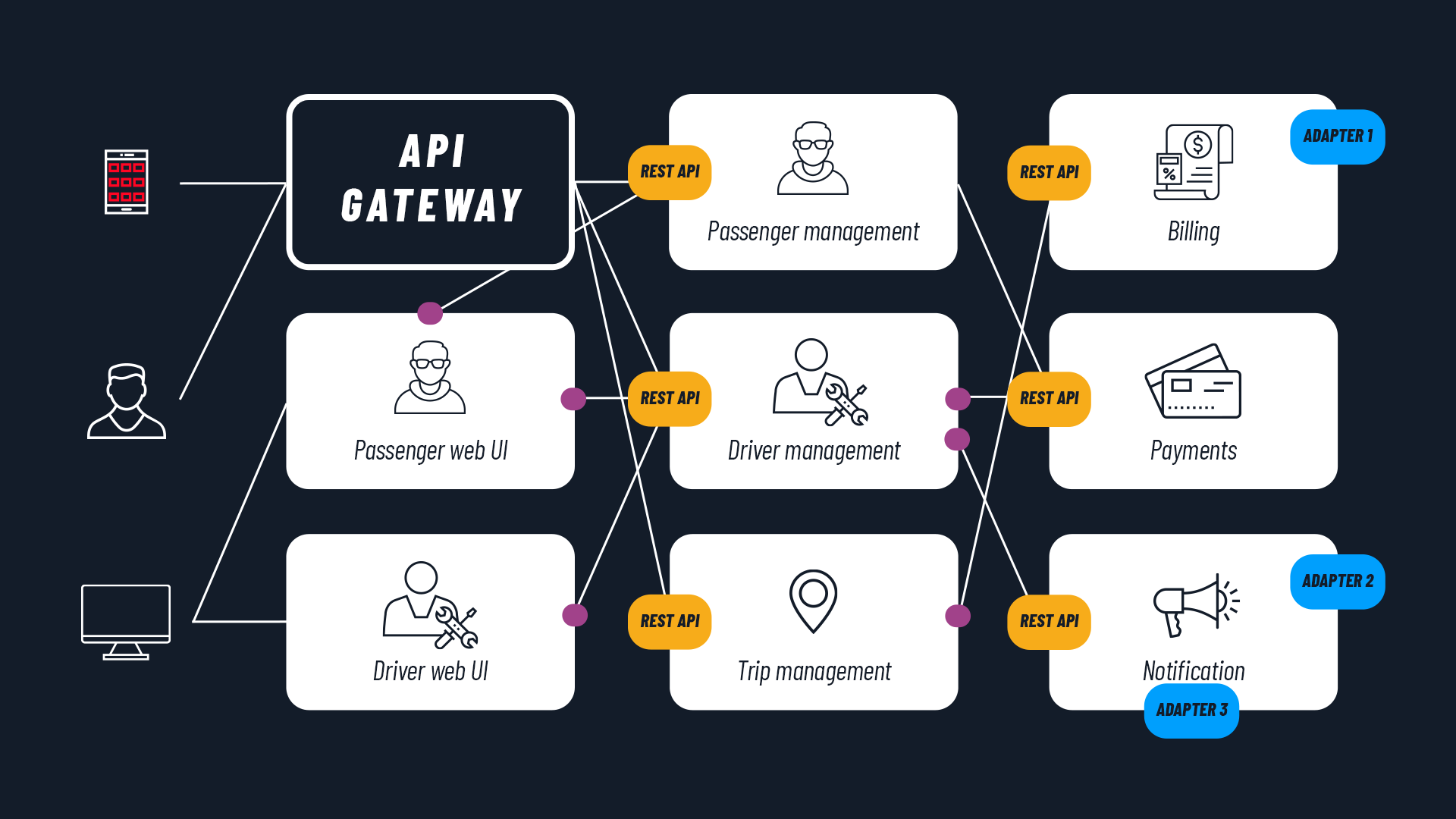


The GitOps paradigm involves using a state store as storage for application manifests (or code), making the state store the single source of truth. What benefits does this practice bring at the organizational, security, and product level?
What is GitOps?
In our first article on GitOps and Kubernetes, we defined GitOps as “a paradigm aimed at implementing Continuous Deployment and/or Continuous Delivery for Cloud Native applications.”
This sentence summarizes the concept of GitOps, for which, however, there is still no universally recognized definition by the community, partly due to its “young age” (the term was first used in 2017). Or rather, there is a still rough proposal that has not been fully adopted.
What is now widely acknowledged are the benefits this paradigm brings: primarily greater observability, security, and productivity.
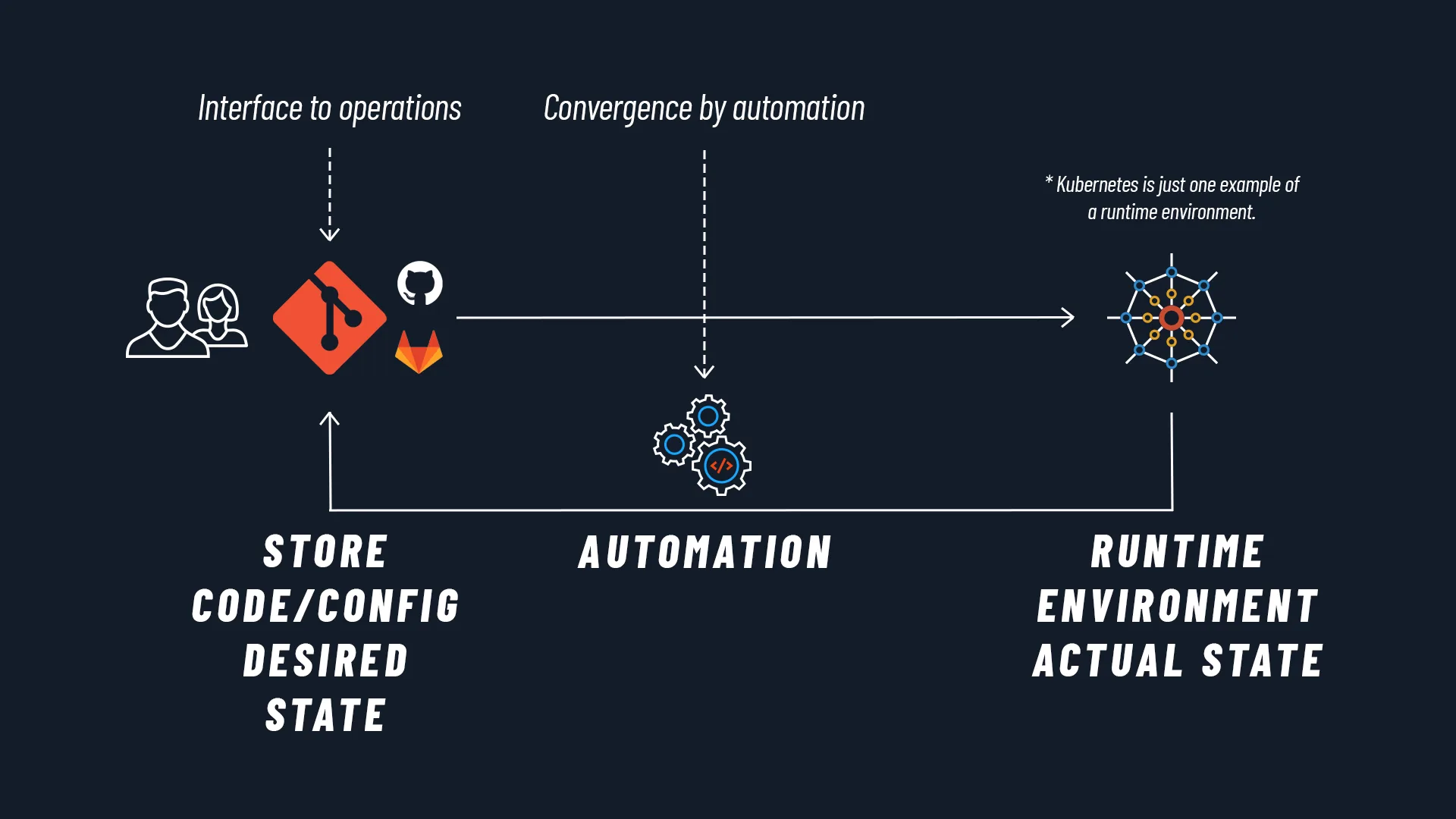
The very name GitOps helps us define its context:
- Git: it is the most widely used version control system in the world, now the de facto standard. In the GitOps paradigm, Git represents the single source of truth for the state of our system. It is in the Git repository that the desired state of the system is versioned.
- Ops: deployment operations are integrated into Git. There is no need to switch tools to deploy the application — everything happens within the version control system used to develop the application.
How does GitOps work?
Despite the progressive automation of processes in the software release lifecycle, infrastructure still requires a lot of manual work. GitOps fits into this context, enabling greater distribution speed, scalability, and infrastructure elasticity.
In essence, GitOps is used to automate the infrastructure provisioning process and help development teams effectively manage the cloud resources needed for continuous release workflows.
Teams that adopt GitOps use configuration files stored as code (Infrastructure as Code). For this reason, in a sense, GitOps is an evolution of Infrastructure as Code that uses Git repositories as the single source of reliability. Git thus becomes the sole reference for creation and updating, and the only control mechanism.
READ ALSO: GitOps and Kubernetes: CI/CD for Cloud Native applications
GitOps vs DevOps: the differences
The similarity with the term “DevOps” is immediately noticeable. So what is the relationship between GitOps and DevOps?
DevOps (and its evolutions such as DevSecOps) are models that promote collaboration between previously separated areas. They are based on the principle of bringing different teams (such as operations and development) closer together to optimize their workflows.
This same approach also applies to GitOps, which, however, focuses entirely on Git. We can therefore consider GitOps as a DevOps best practice. For this reason, DevOps and GitOps are perfectly combinable.
GitOps is also described as a more Cloud Native-oriented way of doing DevOps, which leverages the ability to describe everything at the code level and automation to abstract the Operations team from low-value tasks that can be delegated to machines. At the same time, it allows the Development team to make code changes and push them to production autonomously, without depending on intervention from the Operations team.
Let us also make a necessary premise: although GitOps is a set of best practices applicable regardless of the underlying technology, today it is mainly used in the context of Kubernetes. Kubernetes needs no introduction, being the most widely adopted open source platform for managing containerized workloads and services.
A brief history of GitOps
The term GitOps first appeared in 2017 in a famous blog post written by Alexis Richardson, co-founder and CEO of Weaveworks: “GitOps: Operations by Pull Request”.
Interest in this methodology grew rapidly, both from users who began to implement it and from companies that expanded their offerings with GitOps-based services.
Further confirmation came from the CNCF End User Technology Radar in June 2020, which elected Flux (one of the quintessential GitOps tools) as a technology to adopt for Continuous Delivery in the Kubernetes context. It was now clear: GitOps was rapidly becoming the preferred methodology for running modern Cloud Native infrastructure and applications.
It was on these premises that, in November 2020, the GitOps Working Group was established within the CNCF, with the aim of paving the way towards defining a vendor-neutral GitOps standard.
Don’t miss our Tech Talk on GitOps! Andrea Panisson talks about the state of the art of this paradigm:
Video: Tech Talk GitOps - Andrea Panisson
The principles of GitOps
The principles underlying GitOps contribute to defining the model regardless of its implementation, and in fact they mention neither Git nor Kubernetes. They are:
- The principle of declarative configuration
- The principle of immutability of configuration versions
- The principle of continuous state reconciliation
- The principle of operations through declaration
1. The principle of declarative configuration
The first principle tells us that a system managed by GitOps must have its desired state expressed declaratively in the form of data, in a format that is both human-readable and machine-readable.
The desired state of a system is defined as the set of data sufficient to recreate the system from scratch, so that different instances are behaviorally indistinguishable from one another.
The declarative nature of Kubernetes is therefore the perfect foundation for the GitOps model.
2. The principle of immutability of configuration versions
The desired state must be stored in a way that supports versioning, version immutability, and maintains a complete version history.
We call systems that store the desired state in this way “State Stores”. To quote the definition provided by the community, a state store is “a system for storing versioned and immutable Desired States, which provides access control and auditing on changes to the Desired State”.
In our case, we are clearly referring to the Git repository.
3. The principle of continuous state reconciliation
By reconciliation we mean a process in which the current state of the system is continuously compared and made consistent with the desired state as defined in the State Store.
Concretely, software agents continuously and automatically compare the current state of the system with its desired state. If the current and desired states differ, automated actions are immediately attempted to bring the current state back to the desired state. If they are unsuccessful, the team is notified and can intervene promptly, thereby limiting downtime.
In the Kubernetes context, these software agents are Kubernetes controllers (or Kubernetes operators), and the two that dominate the scene today are undoubtedly: Flux CD and Argo CD. Both are mature projects supported by the CNCF and a large community, with very similar functionality.
4. The principle of operations through declaration
Neither developers nor an external software agent can interact directly with the system. The mechanism through which a change can be applied to the system is through creating a new declarative version of the desired state within the State Store.
And this is a fundamental point, because it means that the only way we can make changes is through a commit to a Git repository.
Git becomes the single source of truth for the system’s state, as well as the only place where we operate. This is why we talk about a developer-centric experience: everything happens within a tool that developers work with on a daily basis.
Why use GitOps?
We can identify 4 major benefits from using these practices:
- Observability: to see what is deployed in the Kubernetes cluster, you simply need to browse the environment repository, with the certainty that it represents the single source of truth. Essential to this are the aforementioned reconciliation process, which works continuously to bring the system back to the desired state, and the automatic alert system in case the reconciliation attempt fails.
- Security: it is possible to reduce security issues arising from exposing Kubernetes APIs to Continuous Integration. This is a great advantage for all companies that want to give access to the production environment to only one or a few people on the Operations team. This type of organization makes it complex to apply urgent changes when the responsible people are unavailable, but thanks to GitOps, changes are made to the repository, effectively eliminating the environment access problem.
- Disaster recovery: we said that the developer is autonomous in making changes. This obviously also applies to particularly urgent cases where the changes made have caused errors: using Git, it is possible to roll back to the previous version of the application relatively simply and quickly.
- Productivity: we can consider this last point as a consequence of all the others. It is clear how adopting GitOps practices leads to leaner workflows and better collaboration between development and operations teams, simplifying problem resolution and eliminating automatable tasks. Concrete evidence of increased productivity is the number of deployments, potentially unlimited and carried out autonomously by the developer.
How to implement GitOps?
There is no single answer to this question, since the best way for teams to implement GitOps depends on specific needs and goals.
However, it is possible to get started with GitOps by following some best practices, for example:
- Using a dedicated GitOps repository for all team members to share configurations and code;
- leveraging automation in distributing code changes;
- setting up alerts to notify the team when changes occur.
More concretely, GitOps requires three main components, some of which we have already mentioned. Understanding and using these three elements is fundamental to implementing GitOps.
IaC
Infrastructure as Code (IaC) was a major step forward for configuration management, as it enabled defining the entire hardware as code, thus accelerating infrastructure provisioning and improving resource utilization. By adopting Git as the prevailing version control system, GitOps has emerged as the latest step forward in the evolution of cloud configuration management.
MRs
Merge Requests (MR) are the change method used by GitOps for any infrastructure update. Through MRs, teams can collaborate with reviews and comments, receive official approvals, and maintain an audit trail.
CI/CD
To understand the GitOps landscape, it is also important to understand how a CI/CD pipeline works. To dive deeper into this topic, we recommend our article on Continuous Integration, Continuous Delivery, and Continuous Deployment.
Is GitOps the right methodology for your company?
Going back to the last benefit mentioned — productivity — we can confidently state that GitOps represents an undeniable business advantage. The simple fact of no longer having to wait to push changes live, being able to fully automate them in a Cloud Native fashion, implies the ability to offer users constantly updated digital services, meeting business needs in short timeframes.
But as with everything, GitOps also presents aspects that may represent a challenge for some companies.
First of all, it is best practice to create two repositories: one containing the application code and one containing the code (manifests in the Kubernetes context) that describes the infrastructure.
Companies that already have a large number of repositories because they manage many applications or because they have different repositories for each microservice, could face a significant increase in complexity. On the other hand, for projects of such scale, a methodology like GitOps becomes a real necessity. In most cases, it is therefore worth facing the increase in complexity in exchange for the numerous advantages that can be obtained.
Implementing GitOps clearly requires effort, so it is important to think in terms of cost-benefit. For example, companies with a well-established DevOps approach may already be able to perform fast daily deployments without GitOps. In these cases, the obtainable benefits might seem smaller, but on the other hand, the implementation time is also drastically reduced.
Even in the case of small-scale applications or websites with limited functionality, the question arises: does it make sense to adopt GitOps? There is no universal answer. What is certain is that the advantages of the paradigm remain: ultimately, it depends on the trust placed in the model and the importance of the benefits relative to the business.
Another point to consider concerns corporate development policies. For some organizations, for example, it is unthinkable to cut the code auditing phase from the process. Normally with GitOps, this phase is automated and does not require operator control: does this mean that GitOps is not possible? Not necessarily — the model is flexible and can be adapted to business needs. For example, it is possible to audit on a branch different from the one the operator is listening to, or on another repository to be approved and synchronized after the review.
In conclusion, is it advisable to implement GitOps?
Ultimately, GitOps is not in itself something new. We can consider it as the natural way of doing operations and DevOps within the Cloud Native and Kubernetes context. In other words, it is a new way of naming some principles and best practices that existed long before the term was coined.
What GitOps adds to these best practices is a true methodology that, as we have seen, the community has been helping to grow and consolidate over the years. Today there are many open points, unanswered questions, and models to be structured, on which we can expect contributions from the GitOps Working Group.
Even without every aspect being clearly defined, the paradigm and its related technologies are at a maturity level that allows them to be adopted by companies without risk. To answer the question with which we opened this concluding section, GitOps is a model that allows you to take an extra step, with measurable benefits and is certainly recommended for most companies that are already operating in the Cloud Native context.