

Born at Google in the early 2000s, SRE is an increasingly adopted approach to ensure reliability and continuous improvement for web products. Let’s explore together what it is, what its pillars are, and the benefits for businesses.
What Is SRE (Site Reliability Engineering)?
SRE is one of the hottest acronyms in the world of software development.
The purpose of the SRE approach is to increase system reliability: it is a set of principles, practices, and organizational constructs that enables both keeping existing systems running and innovating them. This second aspect is crucial, because one of SRE’s goals is not just to keep the promises made about system management, but also to do so while services are constantly being incrementally improved with new features.
Let’s start right away with an important clarification: the word “Site” in the definition should not lead us to think that this approach is only applicable to creating and managing websites. The same principles are in fact suitable for improving the performance of any software system (websites, web or mobile applications, etc.).
Take a look at this video made by our Lead Developer, Marcello Testi, for a complete overview of Site Reliability Engineering:
Introduction to SRE - Site Reliability Engineering
SRE and Google: From Its Origins to Today
SRE practices were born and developed within Google, starting around 2003. More recently, Google decided to make public the approach that enabled the company to build, monitor, improve, and maintain some of the most widely used online services in the world.
To understand the SRE philosophy even before the more practical aspects, we can quote Benjamin Treynor Sloss, the person who coined the term SRE and who is now Vice President of Engineering at Google.
“SRE is what happens when you ask a software engineer to design an Operations function”, the manager said in an interview.
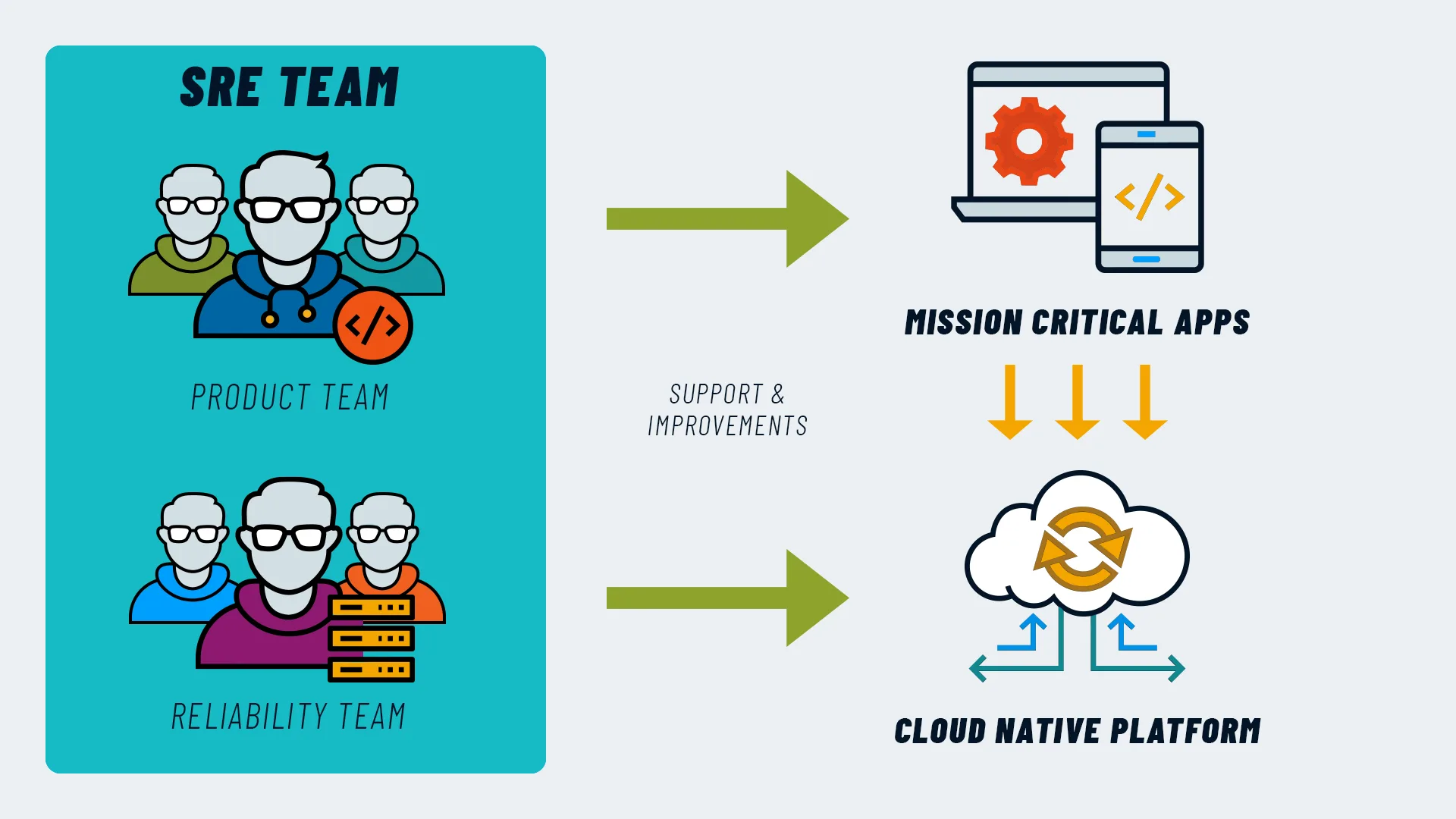
The SRE team or lead therefore performs work that has historically been handled by the Operations team, but does so by adding the mindset and skills of software engineering: a key element is the (typically engineering) ability to replace human labor with automation.
SRE and DevOps: Similar Approaches, but Not the Same
At this point, we cannot avoid mentioning another approach that fosters collaboration between Operations and development teams: we are, of course, talking about DevOps. There is an undeniable closeness between SRE and DevOps, even though the two practices developed independently. Both aim to bridge the gap between the two teams, with the goal of improving the release cycle and product quality.
Despite having similar goals, the two approaches are not mutually exclusive: we can actually see SRE as a concrete implementation of the DevOps approach. SRE embraces the DevOps philosophy but focuses its attention on developing and consolidating practices for measuring and achieving reliability.
In other words, SRE sets operational rules for succeeding in the various DevOps areas. If DevOps focuses on the “What”, SRE is decidedly oriented toward the “How”.
What Does an SRE Team or Engineer Do?
The SRE lead (or SRE team) is responsible for a very broad set of functions, including system availability, latency, performance, efficiency, monitoring, change management, emergency response, and capacity planning.
To understand how crucial this role is in some projects, just read the first line of Benjamin Treynor Sloss’s LinkedIn profile: “If Google stops working, it’s my fault.” Ironic, but not without a grain of truth.
The importance of the SRE role lies not so much in the activities and skills (which are not unique and could also be handled by other teams) but in the modus operandi adopted. The SRE team works with data, which it learns to collect, read, and leverage, and with process automation, which allows for increased control and code normalization. This approach enables reducing the overload of repetitive tasks (the so-called “toil”) and errors.
The Error Budget: What It Is and Why It Matters
The SRE team is also tasked with calculating and managing the error budget. This is a fundamental strategic concept that we could define as the tool used by SRE to balance service reliability with innovation.
The premise of this approach is that systems are dynamic objects that develop and change over time, evolving positively but also bringing a downside: changes are one of the main sources of instability. The error budget provides a control mechanism to shift focus from innovation to stability when necessary.
The SRE team defines an error budget based on a set of metrics (we’ll look at them in a moment) and a time interval in which to measure it. If incidents increase significantly relative to the available error budget, the SRE team’s priority immediately becomes helping to resolve problems by bringing Operations and development teams together to collaborate.
Thanks to the error budget, it is therefore possible to design and plan change without excessively sacrificing availability.
Service Levels: SLI, SLO, and SLA
In order to align all stakeholders on service reliability and availability objectives, SRE introduces 3 key concepts: SLI, SLO, and SLA.
- SLI, Service Level Indicators. These are the metrics used to measure performance or the general behavior of the application. In other words, we could define them as the KPIs to take into consideration. Often these are KPIs that are particularly relevant to users, such as response time or error rate.
- SLO, Service Level Objectives. These are the targets to be achieved for each metric, i.e., for each SLI. The set objectives must wisely balance quality, to be assessed based on business needs, and the costs to achieve it.
- SLA, Service Level Agreement. This includes the legal aspects that come into play if the system fails to meet its SLOs.
It is worth noting that one of the underlying elements of the SRE philosophy is that errors are expected and accepted by all parties involved. SLI, SLO, and SLA serve to set a goal and make it achievable: not by avoiding errors entirely, but by analyzing them after the fact to improve the entire process (and without ever pointing fingers).
FURTHER READING: 6 SRE Best Practices You Should Know
Site Reliability Engineering: The Benefits
Investing your time in developing SRE practices brings a series of easily foreseeable benefits:
- Higher quality
- Constant product evolution
- Reduction of errors and malfunctions
Let’s break down these benefits in more detail and understand the positive consequences for the business and for the working teams.
Constant Control Over the Project
The complexity of some projects is such that it requires a bird’s-eye view, clear and focused on the truly relevant aspects. This is precisely what happens thanks to the advanced monitoring system that SRE requires implementing: the selected metrics allow you to measure key parameters without ever losing sight of the project as a whole.
What you get is a concise and timely view of what happens throughout the project, with valuable information for other business areas as well. Think of marketing, sales, support, but also the main business stakeholders who need to be kept up to date on work status and performance.
Timely Error Resolution
SRE practices have the great advantage of fostering the proactive identification and resolution of software bugs and vulnerabilities. In the absence of a monitoring and automation system like the one promoted by SRE, errors often make their way into production, causing delays, malfunctions, and service downtime.
The consequences for the business and revenue can be very significant; that is why selecting the most relevant KPIs and setting an achievable, well-considered target for each SLI is so important.
Clarifying and Meeting Customer Expectations
Another great advantage of using SLA, SLO, and SLI is the ability to pinpoint end-user expectations from the outset and to develop a plan to meet them.
Having clearly defined service objectives and thresholds allows you to constantly assess work progress and proactively align actions with predefined KPIs. All while keeping the end user and their expectations in mind (with all the benefits this entails in terms of digital services offered, and therefore revenue generated).
Greater Focus on Value Creation
A more efficient system, with fewer problems and where repetitive tasks are automated, is a system that gives the teams working on it more free time. And that time should be invested productively, for example by creating new features or improving existing ones. The Operations team, on the other hand, has the opportunity to dedicate more effort to improving configuration and creating tests capable of identifying potential system defects.
The greater availability of time and reduced stress from errors and delays also leads to greater collaboration across teams, along with the ability to discuss priorities and objectives in a more responsible and creative manner.
Continuous Cultural Improvement
There is one last and very important benefit of SRE: the creation of a culture of collaboration among people and teams, where decisions are made with a clear understanding not only of one’s own work, but above all of the consequences for the user and for colleagues.
SRE fosters an open mindset and greater trust among teams, which materializes on one hand in a better workplace environment, and on the other in the production of high-quality output.









