

_Thanks to serverless architecture, developers can focus on writing code rather than managing servers. How does this increasingly popular approach work?
_
What is serverless computing?
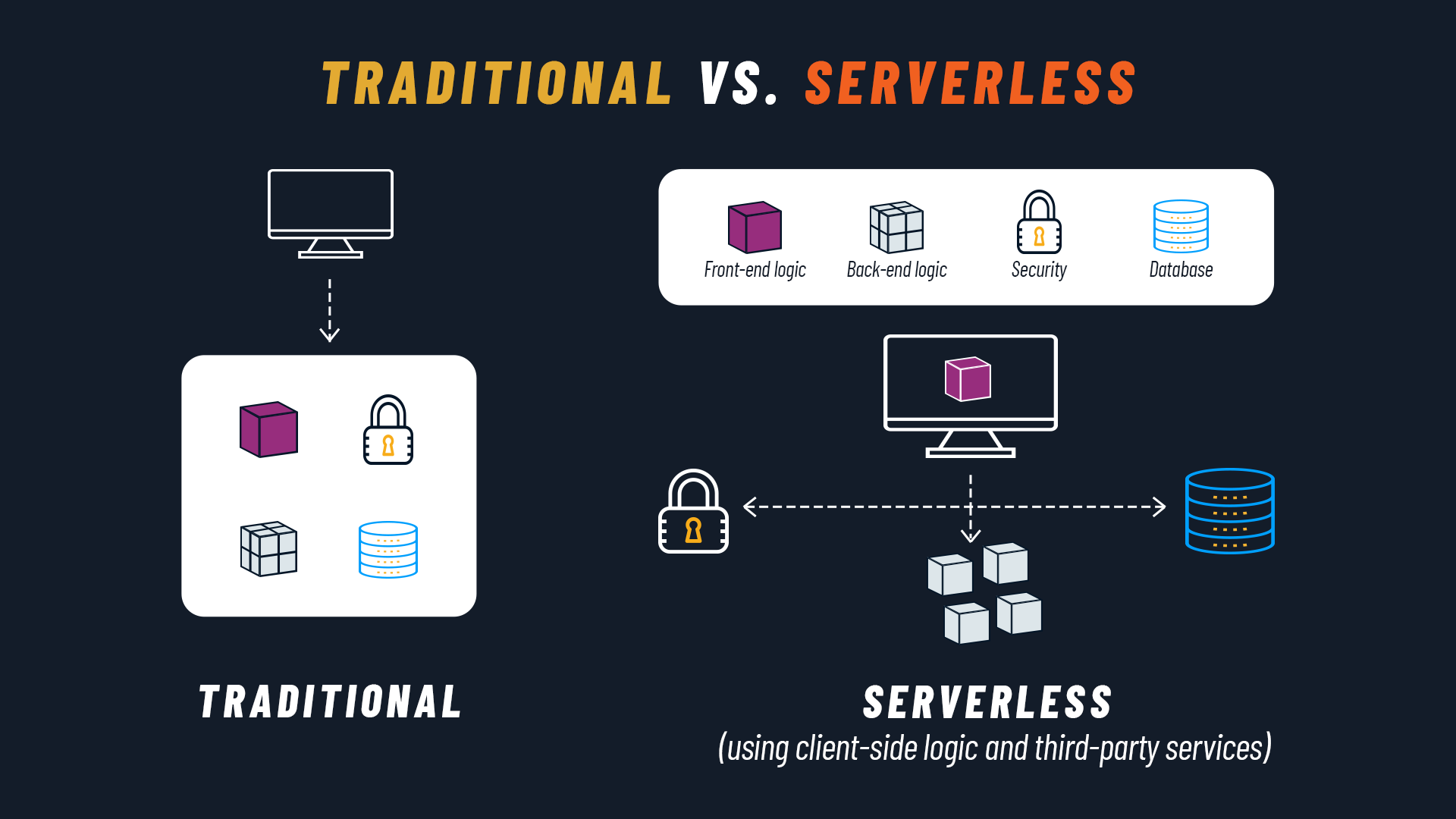
Let’s start with the most obvious question: what is serverless computing? We can define it as a Cloud Native development model in which the Cloud provider manages the infrastructure, dynamically allocating only the computing and storage resources needed to execute a specific piece of code.
Since this process is handled by the cloud provider, developers can focus on the software without worrying about infrastructure. Developers are only required to create and deploy the code for the function or application to be executed, or a container with the code and a description of its dependencies.
The success of the serverless paradigm is also linked to the benefits it guarantees to businesses, such as scalability and cost optimization. The serverless execution model is event-driven, meaning you only pay for serverless functions when they are invoked (pay-as-you-go), with the ability to automatically scale up or down (even down to zero, when there are no requests).
Serverless computing: where did it come from
Before diving into the details, it’s important to make a key clarification. The word “serverless” can be misleading, suggesting that no physical server is involved. That’s obviously not the case: what is serverless, rather, is the developer experience.
In a serverless context, the developer doesn’t need to worry about server configuration, maintenance, and scaling. They can therefore focus on the activity that generates the most value — creating the application code — while the provider handles all infrastructure-related aspects.
The question that naturally arises is: hasn’t it always been this way? After all, the programmer writes code, and the systems administrator runs it on the server. In reality, it’s not that simple. In an enterprise application, there can’t be a complete lack of communication between the two parties: no web project could function if the developer wrote an application for a server that couldn’t run it.
That’s why the need historically perceived by programmers was to be able to focus on writing code without worrying about whether and how it would run on the server. The answer came over time from different fronts: virtual machines, cloud computing, containers, and more recently, the serverless paradigm.
Finally, there’s also a clear economic need for businesses: not paying for the server during periods when it’s not actually serving any requests. The serverless model addresses this need with a pay-as-you-go policy, as we’ve already mentioned.
Two types of serverless services
FaaS (Function-as-a-Service)
The serverless paradigm initially materialized as Function-as-a-Service (FaaS), a service that allows you to run and manage application code as individual functions that are invoked through events or HTTP requests.
We can think of the function as the smallest part of an application (and conversely, the application as a bundle of multiple functions). In some cases, the application may consist of a single function: consider, for example, a chatbot that, upon receiving a question, generates a specific response. The function is executed only in response to an event, such as a user clicking on the chatbot.
With FaaS, developers can build a modular architecture, creating a more scalable codebase without having to spend resources maintaining the underlying server.
Each Cloud vendor has its own serverless offering, the most prominent being AWS Lambda from Amazon, Cloud Functions from Google, and Azure Functions from Microsoft. They allow you to simply upload your code along with any dependencies and automatically deploy it in a container. At that point, the function is available and will be executed when needed, according to the configured events.
Today we’re at a further step: usually when we talk about serverless, we refer to the SaaS (Software-as-a-Service) model meaning an application that is entirely serverless. In this case, we no longer have a single function, but a set of functions, services, and dependencies.
BaaS (Backend-as-a-Service)
In addition to FaaS, another widely cited category of serverless computing products is Backend-as-a-Service.
This model allows developers to access various third-party services. Cloud providers offer, for example, services for user authentication, database management, remote updates, push notifications for mobile apps, cloud storage, and hosting.
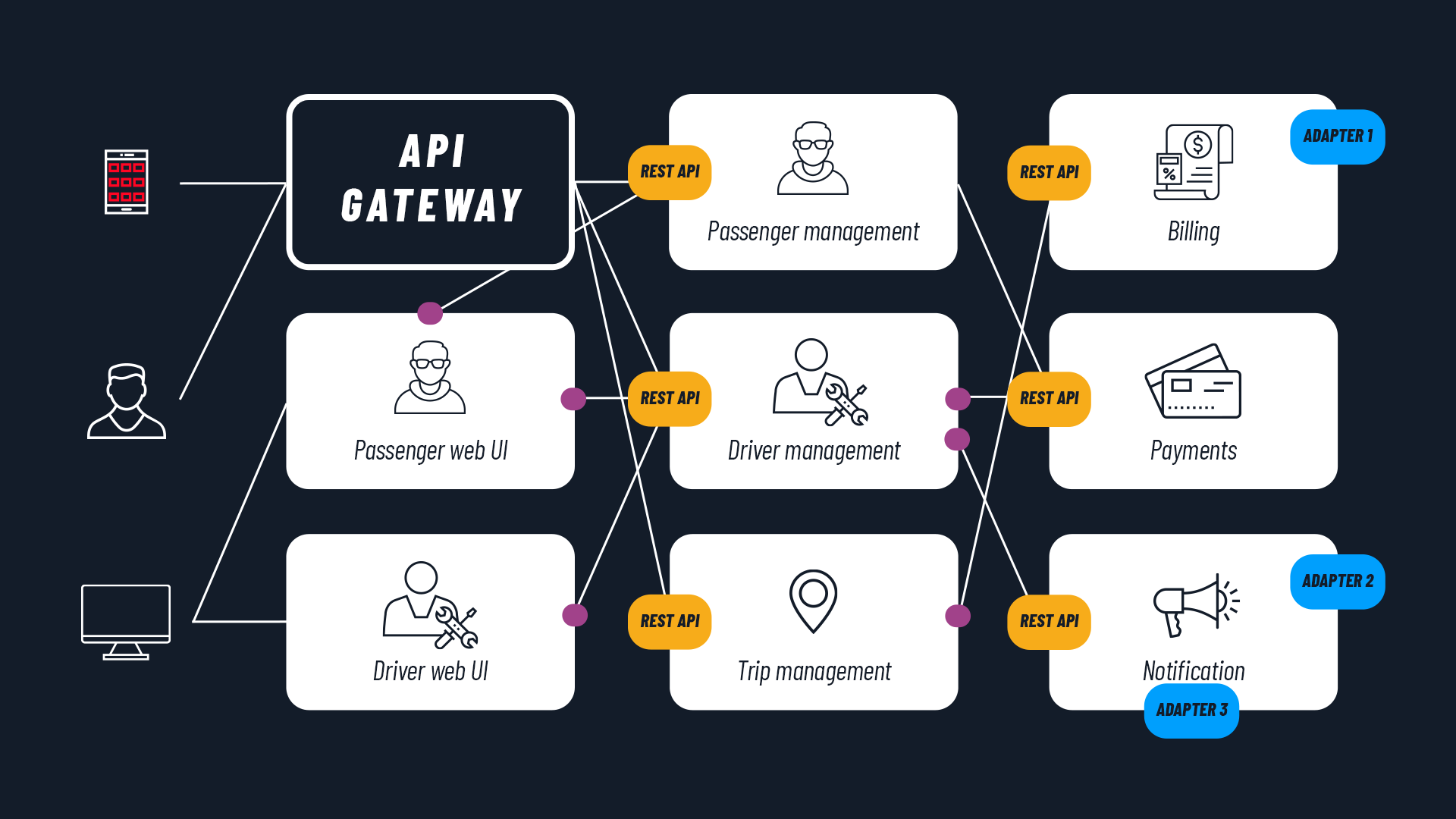
Serverless functions are called via API, so developers can integrate all the backend functionality they need without having to build the entire backend infrastructure.
The most popular serverless providers
According to the Survey Report 2020 by the CNCF (Cloud Native Computing Foundation), 60% of participating companies using serverless choose platforms from the leading public cloud providers on the market: AWS Lambda (57%), Google Cloud Functions (27%), and Azure Functions (24%).
13% opt for installable serverless solutions, the most adopted being Knative (27%), OpenFaaS (10%), and Kubeless (5%).
Finally, for those who want to maintain on-prem infrastructure and create serverless functions or applications, there is an additional option in OpenShift, open source software managed by RedHat. OpenShift can be installed on local machines and allows you to leverage the benefits of serverless even for organizations that, perhaps due to regulatory requirements, cannot share certain types of data with external cloud providers.
What is Knative? Kubernetes Serverless
The container orchestration platform Kubernetes is often used for running serverless environments, but it is not natively designed for this functionality. To address this limitation, Knative was developed — an open source project that adds components for deploying, running, and managing serverless applications on Kubernetes.
With Knative, you can deploy code as a container image and the system starts it only when needed. Knative consists of three main components: Build, Serving, and Eventing, which enable container creation, rapid deployment, and automatic scaling, as well as the use and generation of events to trigger applications.
Unlike previous serverless frameworks, Knative is designed for deploying any type of application workload, from monoliths to microservices and micro-functions. Additionally, Knative can run on any cloud platform that supports Kubernetes, including on-premise data centers, giving businesses greater agility and flexibility in managing serverless workloads.
Advantages and disadvantages of serverless architectures
By this point, the main benefits of serverless are likely already clear. Let’s recap by reviewing the key promises of this paradigm:
No server management and focus on product development: the release and deployment scope is more contained, reducing complexity, (potentially) increasing release frequency and time-to-market
Automatic scaling based on usage
(High) availability and fault tolerance included
Lower fixed costs: you pay for the value and services actually used, with no charges for idle time
Like all solutions, serverless also has drawbacks, such as potential vendor lock-in, difficulty in predicting costs, and cold starts. All disadvantages that, in most cases, do not outweigh the achievable benefits.
If you want to dive deeper into this topic, we recommend our article on the pros and cons of serverless architectures.
Serverless and Cloud Native
When talking about serverless, a reference to Cloud Native is essential. After all, at the beginning we defined serverless precisely as a Cloud Native development model. How are these two concepts connected?
At the foundation of the Cloud Native paradigm is the 12 Factor Methodology: 12 principles that guide development with a Cloud Native approach. They can be concretely implemented thanks to the serverless function, which fully reflects (and respects) them. To cite some points of contact, the serverless function describes the infrastructure, is reproducible, is scalable, and is deployable in isolation.
We recommend this blog post by AWS to explore how serverless interprets each of the 12 principles.
Serverless and microservices: what are the differences?
Microservices and serverless are two important concepts in Cloud Native. Although they are often correlated, they play different roles in modern software environments.
Microservices are an architectural pattern in which applications are broken down into small, independent services. This contrasts with monolithic applications, where all functionality is bundled together.
On the other hand, the serverless approach allows developers to not worry about server management and focus on creating application code. In the serverless model, code runs only on demand, in response to triggers configured by the developers.
Although they are different technologies, microservices and serverless are closely related. Serverless functions can be used to host microservices, thus creating a “serverless microservice.”
It’s important to note that not all microservices run as serverless functions, as some require continuous execution. Furthermore, it’s not necessary to use a microservices architecture to benefit from serverless, although it’s rare for a monolithic application to benefit from being deployed on a serverless platform.
Another difference is that serverless environments can include various functions shared across multiple applications, while microservices are more application-specific and less commonly shared across multiple applications.
In conclusion, serverless and microservices are two complementary technologies in the world of cloud native computing, offering different approaches for designing and running applications. The choice between these two options depends on the specific needs of the project and scalability requirements, but both offer significant benefits for developing modern and flexible applications.
Serverless case studies
The number of companies that have adopted the serverless paradigm has multiplied in recent years.
This growth is also noted by the CNCF in its Survey Report 2020:
- 30% of research participants use serverless computing
- 12% say they are evaluating serverless solutions
- 14% intend to implement it within the next 12 months
Among the most well-known and significant case studies, we must mention Netflix, which as early as 2014 began using AWS Lambda to replace inefficient processes, reduce errors, and optimize turnaround times.
There are several examples in the publishing sector, such as the Seattle Times, the Guardian, PhotoVogue, and ilGiornale.it.
A recent and interesting case is that of Coca-Cola, which chose serverless to implement Coca-Cola Freestyle, a service that allows users to start dispensing their drink via smartphone. Serverless ensures low latency for users and therefore an excellent user experience.
The case studies certainly don’t stop here — they involve organizations of every type and sector distributed worldwide. From e-commerce to online newspapers, from institutional websites to streaming services: serverless architectures have already been put to the test in the most diverse application fields with excellent results.
What is the future of serverless computing?
The adoption of serverless computing is growing rapidly, driven by the need to reduce costs and increase agility. According to a MarketsandMarkets report, the serverless architecture market is expected to triple, growing from $3.3 billion in 2020 to $14.1 billion by 2025.
- An increasingly diverse market: Beyond industry giants like Amazon AWS, Microsoft Azure, and Google GCP, more and more emerging providers will enter the serverless market.
- Greater security: Security is a factor of great importance, as many open source serverless projects have critical vulnerabilities. Greater commitment from customers and developers will be needed to ensure a secure serverless environment. Developers will need to reassess DevSecOps protocols, focusing on data integrity, security, and privacy, to address this evolution.
- Visibility and monitoring: Another challenge for developers concerns the observation and monitoring of serverless applications. Observation and monitoring tools will improve to enable more effective management of serverless applications.
- More attention to environmental benefits: Beyond financial advantages, serverless also offers environmental benefits through reduced energy consumption. The adoption of frameworks like Green Cloud Computing, FinOps and GreenOps will further drive serverless growth.
- Interconnected platforms: Another emerging trend is the interconnection of serverless platforms for cloud, edge, and on-premise environments. This will enable flexible and scalable deployment of serverless applications across different environments, fostering the Internet of Things (IoT), big data analytics, and machine learning. Additionally, there will be new opportunities for creating marketplaces of complex, ready-to-use software systems.
In conclusion, the future of serverless computing offers many opportunities, but will require constant commitment to ensure the security, efficiency, and interconnection of serverless applications across different environments.