---
title: "AgentOps: governing and monitoring AI agents in production"
url: "https://www.sparkfabrik.com/en/blog/agentops-governing-monitoring-ai-agents/"
lang: "en"
type: "blog-post"
date: "2026-05-20"
lastmod: "2026-05-20"
author: "SparkFabrik Team"
description: "Systems based on probabilistic models require a paradigm shift compared to traditional deterministic monitoring. Implement observability strategies to detect hallucinations, decision loops, and token waste. Protect critical flows with AgentOps."
tags: ["AI","DevOps","Cloud Native","Security"]
schema:
"@context": "https://schema.org"
"@type": "BlogPosting"
"headline": "AgentOps: governing and monitoring AI agents in production"
"description": "Systems based on probabilistic models require a paradigm shift compared to traditional deterministic monitoring. Implement observability strategies to detect hallucinations, decision loops, and token waste. Protect critical flows with AgentOps."
"url": "https://www.sparkfabrik.com/en/blog/agentops-governing-monitoring-ai-agents/"
"datePublished": "2026-05-20T00:00:00+00:00"
"dateModified": "2026-05-20T00:00:00+00:00"
"author":
"@type": "Person"
"name": "SparkFabrik Team"
"image": "https://www.sparkfabrik.com/images/blog/agentops-governare-e-monitorare-gli-agenti-ai-in-produzione/featured-en.webp"
"publisher":
"@type": "Organization"
"name": "SparkFabrik"
"url": "https://www.sparkfabrik.com"
"logo": "https://www.sparkfabrik.com/images/logo.svg"
---
# AgentOps: governing and monitoring AI agents in production
**Author:** SparkFabrik Team
**Published:** 20 May 2026
**Tags:** AI, DevOps, Cloud Native, Security
---
{{% tldr %}}AgentOps defines the engineering discipline required to govern, monitor, and secure autonomous AI agents in production. Through reasoning observability and the integration of policy-as-code, this framework allows teams to manage the stochastic unpredictability of generative models. By adopting these practices, companies can transform their internal platforms into intelligent ecosystems, reducing developer cognitive load and ensuring that decision-making automation operates within rigorous and controlled safety perimeters.{{% /tldr %}}
The integration of autonomous systems within enterprise architectures requires a profound revision of software engineering practices. AgentOps is the new discipline that governs the lifecycle of autonomous AI agents, a prerequisite for governance, security, and observability, especially for critical flows in enterprise contexts.
Until recently, application monitoring was based on a fundamental assumption: traditional software is deterministic. Given the same input and initial state, a microservice always returns the same output.
The adoption of Large Language Models has shattered this certainty, introducing **intrinsically probabilistic components** into critical workflows.
This article is aimed at DevOps engineers, tech leads, and platform engineers who are facing an unprecedented operational challenge. It is no longer just about verifying whether a service responds to network requests, but about evaluating whether the decisions made by an autonomous entity are correct, secure, and aligned with business goals. When an AI agent fails, it rarely generates an obvious system error; more often, it produces a semantic hallucination, enters an infinite reasoning loop, or executes unintended API calls.
Traditional monitoring systems, focused on infrastructure metrics such as CPU usage, RAM consumption, or network latency, are completely ineffective against these behavioral anomalies. A Kubernetes pod may appear perfectly healthy on operational dashboards, while inside it, an agent is consuming thousands of tokens in an erroneous decision cycle.
**AgentOps** was born specifically to resolve this void in visibility and control. It is not just a simple set of new software tools, but the necessary evolution to bring autonomous artificial intelligence to an enterprise-ready level.
Embracing this discipline means **extending the engineering rigor typical of Cloud Native environments to the management of the generative model lifecycle**, ensuring that their autonomy translates into a real competitive advantage rather than an uncontrollable operational risk.
## What defines AgentOps compared to traditional operational disciplines?
AgentOps is the engineering discipline dedicated to the management, monitoring, and governance of the lifecycle of autonomous AI agents in production. Unlike traditional IT operations, it focuses on the observability and governance of stochastic decision-making processes, ensuring that multi-agent systems operate in a safe and predictable manner.
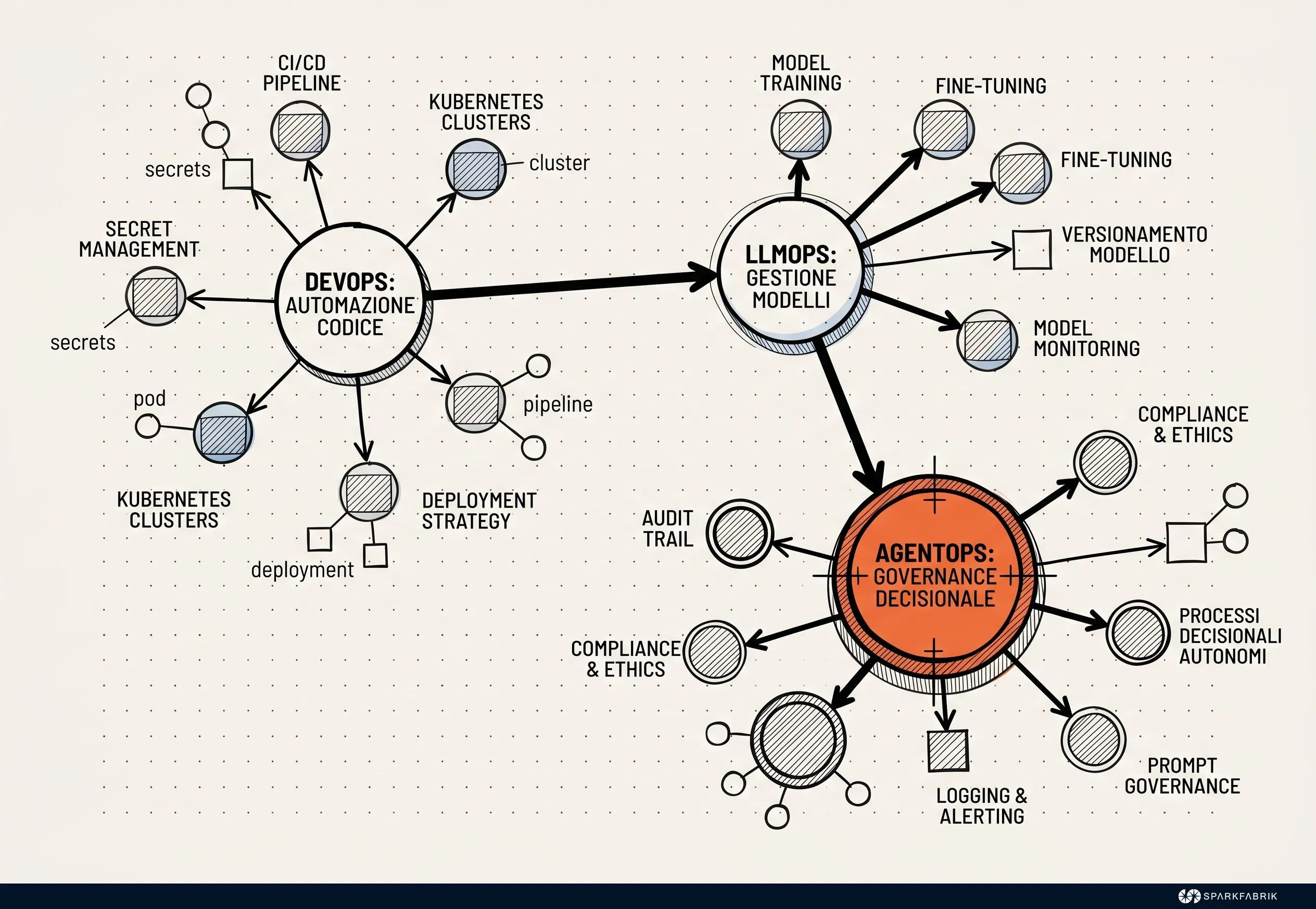
Defining the exact perimeter of this subject requires drawing boundaries with respect to pre-existing methodologies, even though there are obviously deep ties. As highlighted in [recent academic studies](https://arxiv.org/html/2508.02121v1), the epochal shift consists of transitioning from managing machines that execute deterministic instructions to supervising stochastic decision-making entities. A change not only technical, but also mental and approach-based.
AgentOps should not be confused with AIOps, which uses machine learning algorithms to optimize classic IT operations by predicting failures or analyzing logs. Similarly, it is clearly distinct from LLMOps, which is limited to the training, fine-tuning, and deployment of base models. The focus of AgentOps is the behavior of the agent as a whole: the use of tools, memory management, action planning, and interaction with the surrounding environment.
This transition entails a profound **evolution of the DevOps engineer's role**. Infrastructure professionals must now acquire skills to manage semantic unpredictability. It is no longer enough to guarantee cluster uptime; it becomes essential to configure systems capable of intercepting behavioral drifts before they translate into destructive actions.
If the initial goal was to understand what DevOps is to automate code releases, today the challenge is governing artificial intelligence. To explore the origins of this methodological change, we invite you to [learn more about the DevOps approach and its evolution in application development](/en/blog/guides/devops-cosa-e-come-introdurre/).
### The stochastic nature of AI agents
The heart of the operational problem lies in the probabilistic nature of generative models. The challenges of this new paradigm are typically divided between **intra-agent anomalies and inter-agent anomalies** within multi-agent systems. At the intra-agent level, failures take subtle forms: an agent may lose operational context during a prolonged conversation, or suffer from a memory hallucination within a Retrieval-Augmented Generation (RAG) architecture, retrieving irrelevant documents and basing subsequent actions on them.
In multi-agent systems, complexity scales rapidly. Inter-agent anomalies include phenomena such as message storms, where two or more agents enter an infinite loop of requests and responses without ever reaching a conclusion, silently consuming computational budget.
In these scenarios, traditional logs are blind. An infinite reasoning loop does not generate CPU spikes or network latencies significant enough to trigger standard alarms. The infrastructure system works perfectly; it is the autonomous application logic that is flawed. For this reason, operational engineering must shift from monitoring physical resources to semantic monitoring of payloads and chains of thought.
### What are the differences between AgentOps, DevOps, MLOps, LLMOps, and AIOps?
To navigate the complex ecosystem of modern operational methodologies, it is useful to compare the different disciplines. Each of them addresses a specific level of the technology stack, contributing incrementally to business stability and innovation. AgentOps is positioned at the top of this pyramid, orchestrating proactive decision-making automation.
Below is a structured analysis of the main operational disciplines and their impact on business:
| Discipline | Main Focus | Business Impact |
| :--- | :--- | :--- |
| **DevOps** | CI/CD automation and collaboration | Reduced time-to-market, more frequent and reliable releases |
| **DevSecOps** | Integrated security (Shift-Left) | Risk mitigation, compliance, reduced remediation costs |
| **Platform Engineering** | Standardization via IDP | Reduced cognitive load, improved DevEx |
| **MLOps** | ML model lifecycle | Reliable release of predictive models, data-driven decisions |
| **LLMOps** | Large Language Model management | Scalability of generative AI applications, inference cost optimization |
| **AIOps** | AI applied to IT monitoring | Anomaly prevention and intelligent alerting |
| **AgentOps** | Autonomous AI agents for operations | Proactive resolution and decision-making automation |
## What is the operational framework for the AgentOps lifecycle and observability?
The AgentOps operational framework structures the agent lifecycle through development, validation, deployment, and maintenance. It introduces reasoning observability to track decisions and implements remediation cycles to manage semantic anomalies, ensuring rapid and targeted interventions on unforeseen behaviors in production.
Structuring an agent's lifecycle requires a rigorous methodological approach. During the development phase, **prompt definition and tool assignment must be treated as source code**, subject to versioning and peer review.
Validation represents a turning point: traditional unit tests are not enough, making it necessary to adopt patterns like **LLM-as-a-judge**, where specialized models evaluate the quality, relevance, and security of the responses provided by the agent in staging environments.
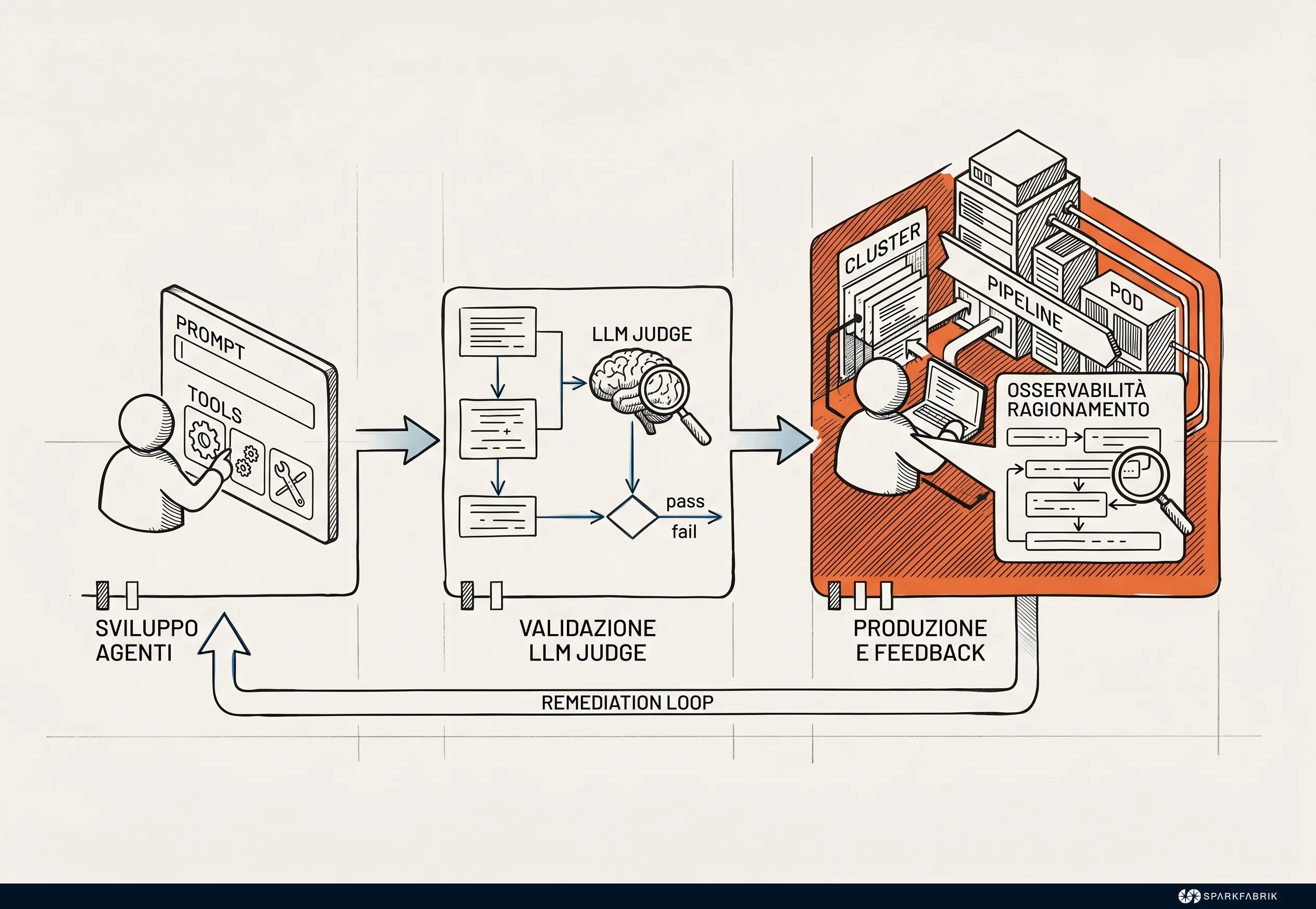
Even in the absence of a specialized LLM, it is advisable to use dedicated skills and different models for the evaluation and generation phases. A fresh and impartial pair of eyes, as in human peer review, is essential. The judge model must typically be different and preferably equipped with superior reasoning capabilities compared to the agent model to avoid self-evaluation bias.
Only after passing these dynamic benchmarks can the agent move to the deployment and subsequent adaptive maintenance phase.
The second pillar of the framework is **reasoning observability**. Tracking an agent's final output is insufficient for debugging a complex error. It is essential to **record the entire chain of thought**, context logs, guardrail activation, and specific calls to external tools.
This level of transparency is fundamental to triggering an effective anomaly management cycle, allowing for accurate root cause analysis (RCA) and the application of targeted resolutions, such as prompt optimization or state rollback. To understand how these principles derive from managing complex systems, [download the free guide on SRE to ensure application reliability](/en/landing/guida-sre/).
### AI Agent reasoning observability and telemetry
Extending Cloud Native observability stacks to support autonomous artificial intelligence is one of the most fascinating technical challenges of AgentOps. Established tools like Prometheus, Grafana, and Jaeger, originally conceived for microservice tracing, are now being configured to support **distributed tracing of decisions made by generative models**. Each step of the agent's reasoning is treated as a span within a distributed trace.
This approach allows engineers to visualize exactly which fragment of context triggered a specific API call or why the agent decided to ignore a specific instruction. However, reasoning observability introduces **unprecedented challenges related to data volume**. High-frequency logging of input and output payloads generates an enormous load on telemetry systems.
Parallel to this, the crucial need to **monitor costs** emerges. Since language model provider APIs bill based on token consumption, an agent stuck in a decision loop can quickly exhaust the allocated budget. Grafana dashboards must therefore be extended to **correlate technical performance metrics with financial metrics** in real-time, implementing automatic circuit breakers that stop execution when spending thresholds are exceeded anomalously.
Similarly, in the case of using local models to ensure maximum data security, observability and cost monitoring are fundamental and present dedicated challenges, requiring, for example, careful measurement of GPU usage and inference times.
### Anomaly management and remediation
Incident response flows specific to artificial intelligence differ radically from traditional ones. When an AI agent exhibits anomalous behavior, the primary goal is to contain the scope of action to prevent damage to infrastructure or corporate data. A concrete risk is tool poisoning, of which a well-known attack vector is Indirect Prompt Injection. The agent receives manipulated data retrieved from an external source that induces it to corrupt the application or execute destructive API calls, such as deleting databases or modifying network permissions.
To manage these emergencies, the AgentOps framework must provide **immediate interruption mechanisms**. Orchestration systems must be able to instantly revoke temporary credentials assigned to the agent or isolate it at the network level, blocking any outgoing communication. Remediation is not limited to containment but requires deep analysis to prevent the incident from recurring.
The integration of **versioning and secure rollback** concepts becomes essential. Every update to an agent's behavior must be treated as a formal software release, whether it is a change to the system prompt, or the addition of a new tool or a new skill (i.e., a set of specific capabilities or functions, such as tool-calling, that the agent can invoke to solve sub-tasks).
If a new behavior proves unstable in production, operational teams must be able to perform a rollback to the previous state in a deterministic way, immediately restoring service reliability while conducting post-mortem analysis in isolated environments.
## AgentOps in platform engineering: how does the Internal Developer Platform evolve?
In the context of Platform Engineering, AgentOps transforms **Internal Developer Platforms**, i.e., centralized portals for developer self-service, into intelligent ecosystems. Autonomous agents raise DevEx and reduce cognitive load, orchestrating complex resources, enabling self-service, and operating within perimeters well-defined by corporate policies.
Market data confirms that we are in a phase of profound architectural transformation. The [ESG and Google Cloud report](https://globalitresearch.com/whitepaper/analyst-report-esg-building-competitive-edge-with-platform-engineering-a-strategic-guide/) highlights how 55% of companies globally have already adopted platform engineering practices, and over 90% expect to expand their use in the coming years.
This massive adoption creates the **perfect infrastructural ground for AgentOps**. Centralized platforms provide the APIs, orchestration tools, and identity management systems necessary for AI agents to operate at scale.
**Developer Experience (DevExp)** is a fundamental parameter in Platform Engineering to measure a team's engineering effectiveness. AI agents integrated into an IDP revolutionize this experience.
The ongoing transition sees Internal Developer Platforms evolving from static self-service portals, where the developer must fill out complex forms, into truly intelligent and proactive ecosystems. However, this efficiency cannot exist without ironclad governance: automation must be bound by policy as code to prevent misconfigurations.
To learn more about the impact of these dynamics on team efficiency, we recommend reading [how to improve Developer Experience to reduce team cognitive load](/en/blog/dx-developer-experience-guida/) and our dedicated guide.
### From static portals to intelligent ecosystems
The evolution of internal platforms is driven by the need to **reduce the cognitive load on development teams**. In a modern microservices architecture, requesting the provisioning of a new environment involves configuring repositories, CI/CD pipelines, Kubernetes clusters, databases, and network policies. Requiring developers to master every single tool drastically slows down software delivery.
**AI agents solve this bottleneck by orchestrating resources autonomously.** A developer can interact with the platform in natural language, requesting, for example, a staging environment optimized for load testing on a specific service. The agent analyzes the request, deduces the necessary dependencies, generates infrastructure manifests, and initiates dynamic resource provisioning, notifying the user once the operation is complete.
The reduction in cognitive load is immediate and quantifiable, and the business value generated by this transition is twofold. On one hand, accelerated onboarding is achieved: new hires can become productive in days rather than weeks, guided by the agent through the complexities of the corporate infrastructure. On the other hand, senior developers' time is optimized, freeing them from repetitive operational tasks to focus on writing business logic and architectural innovation.
## AgentOps and DevSecOps: security as a prerequisite in the era of autonomous agents
**The autonomy of AI agents generates value only if they operate within a defined and automated security perimeter.** With AgentOps, DevSecOps ceases to be a best practice and becomes an infrastructural prerequisite: every autonomous action, from resource provisioning to configuration modification, must be validated before reaching production. The Shift-Left approach, which integrates security from the earliest stages of the software lifecycle, becomes the architectural principle upon which to build trust in autonomous systems.
### How to validate agent actions in DevSecOps pipelines?
Practical implementation requires AI agents to operate within a rigorous and immutable DevSecOps pipeline. **Every proposed change generated by an AI agent must be treated as a standard pull request**, subject to the entire chain of automated checks. There are no exceptions: whether the action was produced by an engineer or an agent, the validation process is identical.
This means integrating the right operational tools directly into the agent's workflow. Every infrastructure change generated by AI, before being applied, must pass through **static security tests (SAST)**, which analyze the proposed code for known vulnerabilities, and **dynamic tests (DAST)**, which verify application behavior at runtime. This happens directly in CI/CD pipelines, thus validating the actions proposed by agents before deployment.
**Container scanning systems** complete the picture, confirming that the images used do not contain compromised dependencies. If an agent suggests updating a library to fix a performance bug, the scanning verifies that the new version does not introduce known vulnerabilities. Only after passing these checks can the change proceed.
Furthermore, in some advanced AgentOps frameworks, signals produced by these processes, such as pipeline rejections, approvals, false positives, scan results, and other specific instructions, become feedback that progressively refines the agent's behavior. A system that learns and improves its security posture with use.
### Policy as Code and security guardrails
The autonomy granted to agents within the platform requires the definition of rigid and impassable boundaries. The governance of this process is based on the adoption of **Policy as Code**. In the AgentOps field, security is implemented through two distinct types of controls: policy guardrails, which limit concrete infrastructure actions, and AI guardrails, which semantically filter the inputs and outputs of language models.
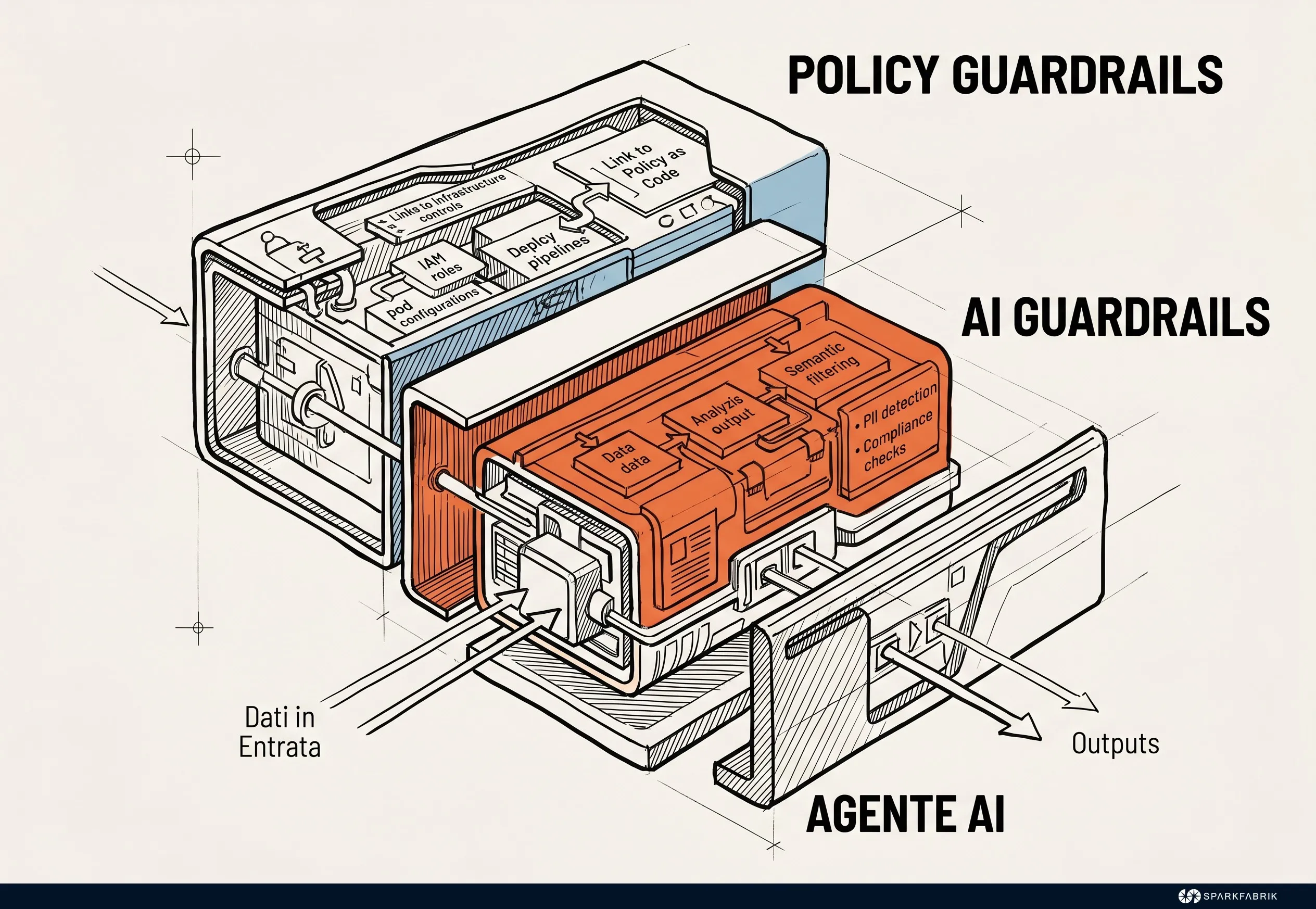
**Policy guardrails** are infrastructure constraints that limit the agent's actions and circumscribe its effective scope. Using **standards like Open Policy Agent**, companies define rules that prevent artificial intelligence from performing non-compliant or destructive operations (such as exposing a database on public networks), regardless of the instructions received or the model's deductions.
A concrete example clarifies the importance of these constraints: imagine an agent tasked with cloud cost optimization that identifies an apparently underutilized Web Application Firewall (WAF) and decides autonomously to turn it off to save resources. Without infrastructure policies, the action would be executed, exposing the company to critical risks. Policy guardrails intercept the API call, block it in milliseconds, and return a compliance error to the agent.
Another distinct but related concept is that of **AI guardrails**. These are systems that **filter the agent's semantic input and output**, blocking the generation of harmful content or masking sensitive data before it is sent to language models. They are also used to block prompt injection attempts and responses not in line with the brand, avoiding equally serious reputational damage.
These filters also contribute to the security of corporate applications that integrate AI functionality, and require detailed monitoring and logging to verify their effectiveness.
A practical example is illustrated in our deep dive on [AI Guardrails in Drupal](/en/blog/guardrails-ai-in-drupal-agenti-e-gestione-avanzata/): a SparkFabrik contribution to the open source ecosystem that demonstrates how to configure advanced security filters for incoming and outgoing data.
## How is AgentOps applied in real operational contexts?
AgentOps applies transversally to infrastructure and software. Monitoring and governance rules govern both Virtual SREs for proactive Kubernetes cluster management and application agents that automate software delivery, customer care, and marketing operations.
Demonstrating the universality of the AgentOps framework is fundamental to understanding its strategic scope. The most common mistake is relegating this discipline exclusively to chatbot monitoring. On the contrary, **observability practices, semantic failure management, and the imposition of guardrails** apply with the same effectiveness to both base infrastructure and high-level application software. **Engineering principles do not change as the agent's domain of expertise varies.**
To fully understand the foundations upon which these infrastructure agents operate, consult our [complete guide to Kubernetes for container orchestration in complex environments](/en/blog/guides/kubernetes-guida-completa-orchestrazione-container/).
### Virtual SRE for infrastructure operations
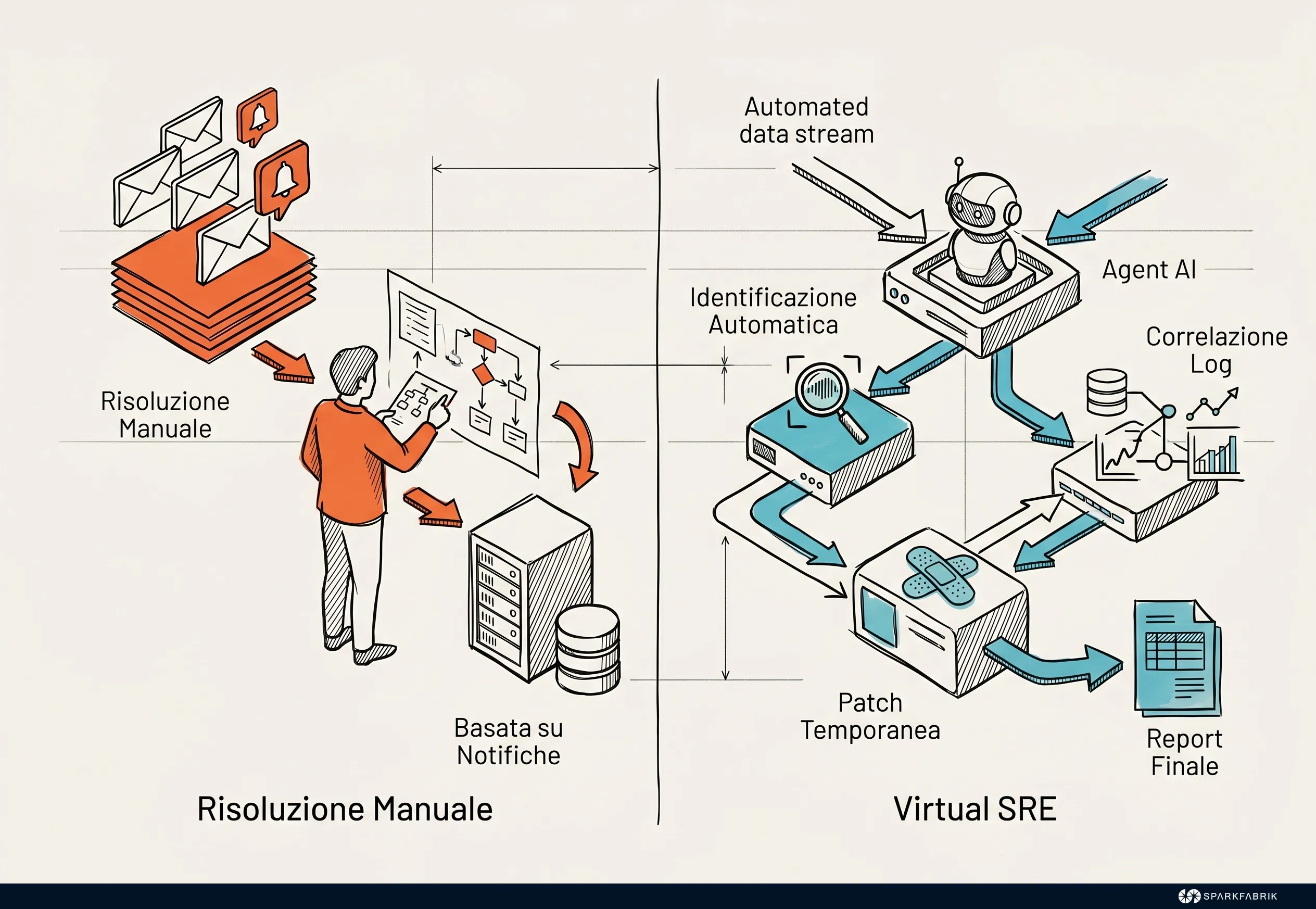
A **Virtual SRE** is an autonomous agent designed to identify, diagnose, and resolve incidents in production without requiring continuous human intervention. Unlike traditional passive copilots, it operates as an active extension of the engineering team, marking one of the most advanced milestones of AgentOps applied to infrastructure.
Imagine an operational scenario on a Kubernetes cluster: a microservice begins to manifest a progressive memory leak over the weekend. Traditional alerting systems would send notifications to an on-call operator, requiring manual intervention to analyze logs, identify the problematic pod, and restart it.
A Virtual SRE (or SRE agent), equipped with the appropriate tools, intercepts the anomaly in real-time. The agent correlates memory consumption metrics with recent application logs, identifies the probable cause, and applies a temporary configuration patch, such as increasing memory limits or controlled pod restarts, notifying the team with a detailed report of the already resolved incident. This level of automation requires deep observability to ensure that the agent's actions do not cause cascading service disruptions.
Similar scenarios apply to CI/CD pipeline optimization. Operating on complex cloud environments, an agent can analyze test execution times by interacting directly with Git repositories. If it detects that an end-to-end test suite systematically slows down releases without finding significant bugs, the agent can propose a reorganization of jobs or more efficient parallelism, opening an automated pull request to modify pipeline configurations.
It is crucial to emphasize that AgentOps does not replace operational teams, but empowers them. **The Virtual SRE works alongside human teams 24/7, but strategic control remains firmly in the hands of engineers.** Enabling this level of collaboration requires deep observability, continuous monitoring, dedicated training, and a strong propensity for experimentation.
### Application agents for software delivery and workflows
Shifting the focus away from infrastructure, AgentOps demonstrates its value in managing agents specialized in application domains. In software delivery, coding agents do not just suggest code snippets, but generate entire features, perform pull request reviews, and write unit tests autonomously. The AgentOps framework ensures that the generated code meets corporate standards through automated static analysis.
A rapidly expanding area is **agentic marketing**. In this context, AgentOps governs complex systems that analyze the performance of hundreds of advertising creatives, recreate them while respecting the corporate tone of voice, and orchestrate batches of A/B tests in complete autonomy. Other specialized agents take care of generating and optimizing dynamic landing pages based on user behavior. Although the domain is creative, the need for governance is purely engineering-based.
Furthermore, **other application scenarios exist in customer care, commercial processes, and logistics**, where agents manage complex interactions with customers or optimize supply routes by processing massive amounts of data in real-time.
Managing these workflows requires the same operational guarantees as infrastructure. The need to implement session replay functionality to analyze past interactions, continuous quality assessment through judge models, and autonomy limitation to prevent reputational damage or budget waste remain identical. **AgentOps provides the control structure necessary for artificial intelligence to operate safely in any business process.**
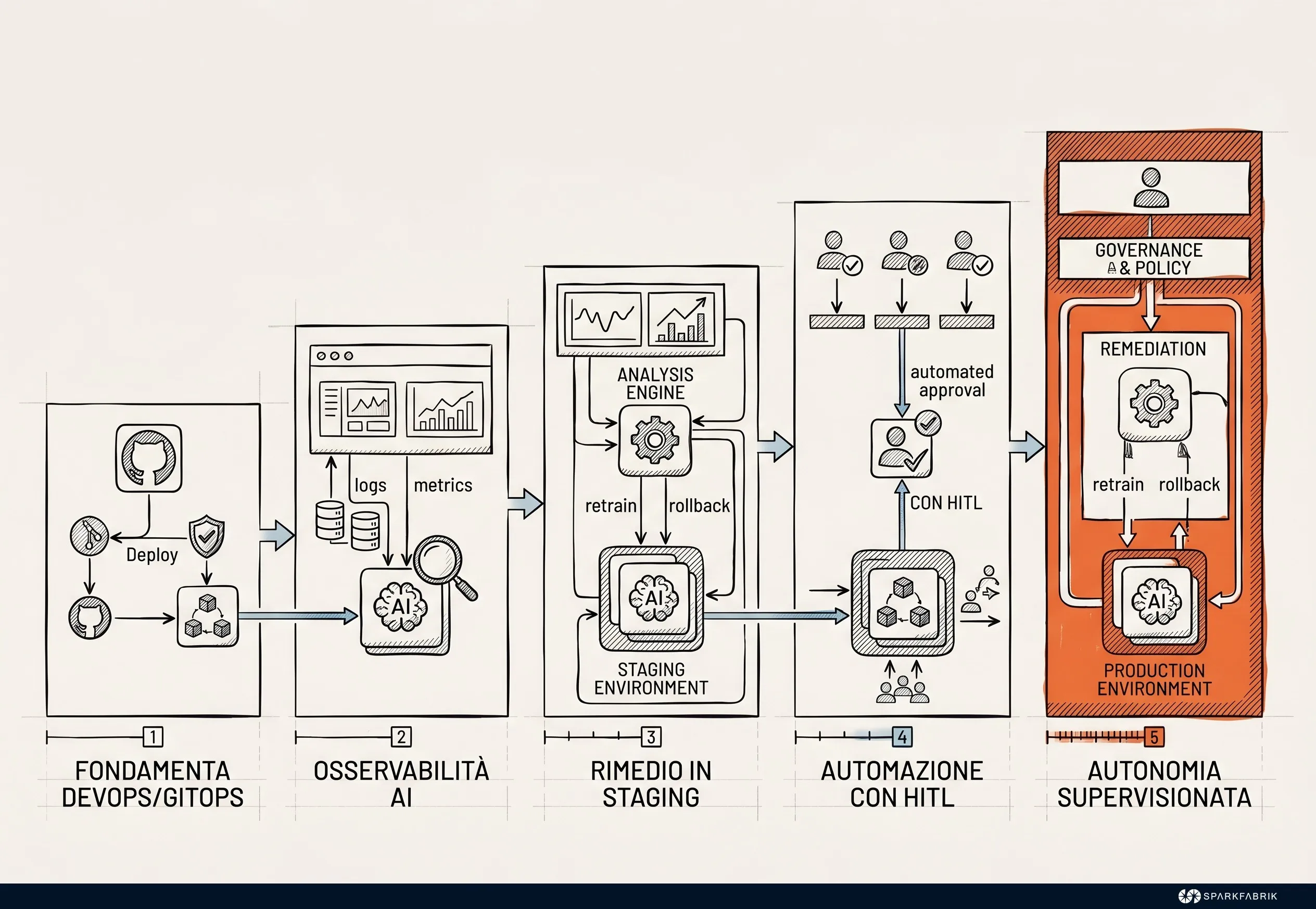
## How to structure an AgentOps adoption roadmap?
AgentOps adoption requires a pragmatic roadmap that starts with consolidating Cloud Native foundations. Through a human-in-the-loop approach, teams build trust in the system by validating decisions in read-only mode, before delegating low-risk operations to supervised autonomy in production.
Providing a clear guide to technology leaders is essential to avoid the typical failures of unstructured innovation projects. The path to AgentOps cannot ignore the **consolidation of pre-existing automation practices**. Implementing intelligent agents on manually managed or non-versioned infrastructure does not lead to efficiency, but amplifies technical debt.
To explore the strategic impact of this transformation, [discover how intelligent agents transform processes and business](/en/landing/agenti-ai-processi-aziendali/).
The evolution toward autonomy typically unfolds through a logical progression:
1. **Assessment and GitOps standardization:** Companies must map their operational processes, identify bottlenecks, and ensure that infrastructure is declarative and deployments are fully automated. Attempting to apply AgentOps to manual processes means delegating the management of chaos to artificial intelligence. Furthermore, DevSecOps pipelines become the mandatory gates through which all agent actions pass. Without DevSecOps, giving an agent autonomy is dangerous.
2. **AI-Assisted Observability (read-only):** Agents are introduced without any modification permissions. Their task is to analyze huge volumes of logs, correlate events from distributed systems, and generate advanced incident reporting. This allows teams to calibrate telemetry systems and evaluate reasoning accuracy.
3. **Remediation in non-prod environments:** Agents obtain permissions to apply architectural changes and resolve incidents, but exclusively in development and staging environments. Within this controlled perimeter, self-correction capabilities are tested and policy guardrails are refined.
4. **Human-in-the-loop automation in production:** Agents monitor production clusters and propose detailed resolution plans, but actual execution requires the explicit approval of a senior engineer. This ensures absolute safety in high-stress real-world scenarios.
5. **Supervised autonomy:** After months of validation, specific, low-risk operational tasks, such as cloud cost optimization or predictive auto-scaling, are fully delegated to agents. The emphasis shifts to the robustness of orchestration systems, capable of isolating the agent at the first sign of an anomaly.
### Managing AgentOps uncertainty as an emerging technology
Integrating AgentOps requires strong **alignment of expectations** at the executive level. CTOs must promote an **organizational culture** characterized by a marked **propensity for experimentation** and a healthy **tolerance for initial failures**. Language model "hallucinations" represent a concrete risk, and as these are emerging technologies, it is natural to explore various mitigation strategies.
To safely manage these uncertainties, it is imperative to design systems that provide for **instant rollback actions and infrastructure immutability**. If an AI agent applies an incorrect configuration, the orchestration system must be able to quickly restore the previous state. Resilience is an increasingly central value in modern architectures and becomes the prerequisite for safely experimenting with autonomous automation.
**The "human-in-the-loop" approach proves essential** not only as a security measure but as a tool for organizational learning. The transition from a purely AI-assisted approach (where the agent suggests and the human approves) to an AI-autonomous one must be gradual. This allows engineers to build trust in the models' decision-making capabilities before loosening operational constraints, and to maintain human intervention for the most critical operations in production.
## Conclusion
AgentOps does not represent a passing trend destined to fade with the artificial intelligence hype cycle. On the contrary, it establishes itself as a profound structural evolution, essential for managing the increasing complexity of modern distributed systems.
Delegating operations to stochastic decision-making entities requires a **new approach**, where reasoning observability and proactive anomaly management become the new success metrics for operational teams.
It is fundamental to reiterate that the success of autonomous artificial intelligence in production rests entirely on the solidity of infrastructural foundations. Without a mature Cloud Native architecture, devoid of rigorous DevSecOps practices and declarative resource management, AgentOps risks amplifying existing inefficiencies. Intelligent automation does not correct flawed processes; it simply executes them at a higher speed.
CTOs, Tech Leads, and infrastructure managers must objectively evaluate the maturity of their Internal Developer Platform and internal security skills before delegating critical operations to AI agents. **Building intelligent ecosystems requires planning, specialized skills, and a security-by-design approach.**
If you wish to explore how our experience can accelerate this transition in your company, [discover how we integrate intelligent agents into business workflows](/en/servizi/ai-development/) and book a consultation to [tell us about your project and your challenges](/en/contatti/).
---
## Frequently Asked Questions
### What differentiates AgentOps from traditional DevOps practices?
Traditional DevOps is based on deterministic automation scripts, which execute predefined instructions with predictable results, reducing time-to-market. AgentOps represents the natural evolution of these practices: it governs autonomous and stochastic AI agents, capable of reasoning about context and making dynamic decisions. This evolutionary leap requires new approaches for reasoning observability, semantic anomaly management, and the implementation of security guardrails.
### What are the main risks in entrusting infrastructure to AI agents?
The main risks include semantic hallucinations, where the agent makes decisions based on incorrect contexts, and tool poisoning, a vulnerability often triggered by Prompt Injection that can induce destructive API calls. To mitigate these risks, AgentOps mandates the use of policy as code to limit permitted actions, AI guardrails to filter inputs, and requires orchestration systems capable of executing instant rollbacks in case of failure.
### How does AgentOps improve the developer experience (DevExp)?
AgentOps transforms Internal Developer Platforms from static portals into intelligent ecosystems. Developers can request the provisioning of complex resources in natural language, delegating the configuration of dependencies, databases, and network policies to the AI agent in minutes. This drastically reduces cognitive load, accelerating the onboarding of new hires and freeing up valuable time for architectural innovation.
### What infrastructural prerequisites are needed to implement AgentOps?
To successfully implement AgentOps, companies must possess solid Cloud Native foundations. It is essential to have adopted GitOps practices for configuration versioning, automated CI/CD processes, and declarative infrastructure. Applying autonomous agents to manual or untraceable processes amplifies technical debt and compromises the stability of systems in production, making effective root cause analysis impossible. DevSecOps pipelines become essential to ensure the application of the same security measures to agents and human supervisors.
---
## Related Articles
- [The illusion of universal AI: why access to frontier APIs will become exclusive](https://www.sparkfabrik.com/en/blog/illusion-universal-ai-frontier-apis/) - Artificial intelligence does not follow the logic of traditional zero-marginal-cost software. …
- [AI agent harnesses: the great pricing divergence](https://www.sparkfabrik.com/en/blog/ai-agent-harness-pricing-divergence/) - The real value of artificial intelligence no longer lies solely in the model, but in the …
- [DDD 2026: AI in Drupal development, beyond the hype and with ethics](https://www.sparkfabrik.com/en/blog/drupal-ai-development-ethics-ddd2026/) - The integration of language models into the open source CMS is moving past the experimental phase to …
---
*This is a Markdown version of the blog post to facilitate reading by AI and crawlers.*
*Visit [https://www.sparkfabrik.com/en/blog/agentops-governing-monitoring-ai-agents/](https://www.sparkfabrik.com/en/blog/agentops-governing-monitoring-ai-agents/) for the full version with images and formatting.*


